这篇文章最大的亮点就是与传统的直推式矩阵补全方法不同,提出使用学习Enclosing Subgraph来进行填充!
先说结论:
-
IGMC基于GNN归纳学习与评分矩阵相关的局部图模式,而不是传统的transductive latent features;
-
IGMC 不依赖side information of user/item;
-
能够迁移到new tasks without any retraining,a property much desired in those recommendation tasks having few training data. (Amazing!!)
问:那么什么是所谓的直推式?
答:通过将rating matrix 分解成 行(user)和列(item)的低维潜在嵌入的乘积, 但是学习到的嵌入只能在该系统user&item没有新增的情况下work,并不能推广到unseen的row&col,或者new matrix!
问:那我可以使用聚类的方法呀,将新加入的user|item与现有的user|item进行cluster,那不就可以解决unseen的情况了吗?
答:是的!most previous works都尝试过使用side information,比如user’s age、movie’s genre等,但是面临着一个问题必须要解决:我需要高质量的side information, 对于用户,可以从他们的profile提取,但是!极端的情况下,没有辅助信息!?!
问:那这篇论文没有使用到side info. 也能做到?有点不可思议吧!
答:听我慢慢道来!
论文中的作者提出了IGMC,仅使用 由评分矩阵生成的(user, item)pairs 对周围的1-hop子图来训练GNN,并且map 1-hop子图 to their corresponding ratings!
亮点:
-
仅利用(user,item)pairs,没有用到辅助信息;
-
在1-hop子图训练GNN;
-
对subgraph评分;使用回归模型来拟合target user&item pair的rating!
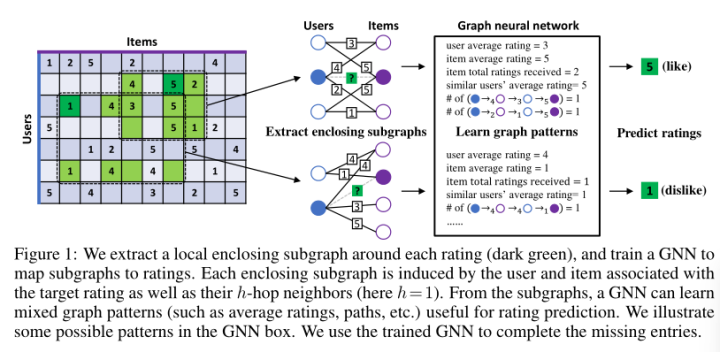
简单来说就是,用户A给电影B打了5分,然后子图提取的使用,在rating matrix 中以 A-5->B为中心提取出1-hop子图,并将提取到的子图放到GNN里面去学习,用户A究竟给电影B打了多少分!
Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.
那模型的效果怎么样捏?
那必须很厉害!不然我也不会和大家分享8~
工作总结:
-
IGMC实现并没有使用到辅助信息,但是达到非常好的效果;
-
基于(user, item)pair的local graph patterns能为特定的user预测其对特定item的喜好程度;
-
Long-range dependencies might not be necessary for modeling recommender systems.
仅解释上面的第三点:论文主要用了1-hop提取封闭子图,虽然也提及了2-hop子图效果会好上一丢丢,但是训练模型时需要花费更多的时间。1-hop&2-hop其实都没有考虑到一整张图呀,其实也就是说user并没有考虑到Long-range dependencies咯~
问:既然这么厉害,那模型架构总体架构是怎么样的?每一步都做了些什么事情呀?!
答:不要急!马上给你介绍得明明白白~
首先,先介绍几个定义:
G: 表示一个无向二分图结构(undirected bipartite graph graph),它是constructed from the given rating matrix R.
R: 用户对item的所有可能的rating, e.g., R = {1,2,3,4,5};
N_r(u): 用户u的邻居中,打分为r所构成的集合!
首先登场的是:enclosing subgraph extraction
把大象装进冰箱~
-
在评分矩阵中,对于每一个非0的cell,都以它为中心提取一个h-hop的子图G;
-
将提取到的h-hop封闭子图送到GNN中,我要用这个子图来预测用户究竟打了多少分!预测的方法其实也很简单,就是学习到user&item的embedding之后送到一个MLP进行回归~

Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.
Attention!! 因为MLP需要预测target(u, i)的rating,因此把子图feed给GNN之前记得把 真实的rating mask掉~不然还拟合个啥~
其次:Node Labeling
IGMC的第二步是节点标记!发生在子图feed给GNN前,为图中的每一个节点提供一个新的整数标签!
目的:使用不同的标签来标记子图中不同的节点;
理想的情况下,标签能够:
-
能够在target rating 的位置区分user&item; 打上标签就能区分!
-
区分user类型的节点&item类型的节点! ? 这里该如何区分?因为user&item的id都是一个整数标签!应该需要在打标签的时候做一下手脚~
那作者是怎么做的?
-
目标节点: 为目标user&item标上 0&1;
-
其他节点:在算法1中,如果在i-hop user 的id则标为2i,item的id则标为2i+1 (其实,节点不加区分!只有远近关系!第ith 所有的user都为2i;item都是2i+1)
这样做有什么好处呀?
-
充分区分目标节点&
上下文节点; -
标签的奇偶性用来区分节点类型;
-
序号越大,node与target node的距离就越远~ 这里其实说的是一个long-range dependence的问题!
感觉这个很妙~那我也可以自己想一个~不过要在数据中验证自己的猜想才行~~可真不简单呢
再次:GNN架构
GNN是通过子图来学习user&item的embedding的!学习出来之后呢才可以feed到MLP中进行回归~
GNN包含两部分:
-
信息传递层需要为图中的节点提取特征向量;
-
使用pooling 从节点特征中概括子图表示
在这里, 论文作者是用来relational graph convolution operator (R-GCN)作为消息传递层

Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.
对重要的一下参数做一下解释:
w_r^l是需要共享的参数矩阵,对于每一个rating 比如R = {1,2,3,4,5}这里就需要由5个w_r^l!
后面两个求和在干嘛?
其实是在做一个平均&求和,target user与很多个邻居 user以rating = r进行关联,那么我们看看其他user对target item的评分是多少;
假如把邻居user当作是我的朋友,他们对某一个部电影的评分的平均就可以当作是我对它的评分!!因此,我对movie的喜好程度从某次层面来说是所有朋友共同决定的!
最终得到的embedding是啥?
![]()
Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.
消息passing做完了,后面就是pooling了!
论文中作者做的Pooling可能与传统上的不一样!因为我过去学习CNN时,一般用的是sum、max、average等
论文作者怎么做?
![]()
Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.
其实也是拼接起来~
emmmm~~~
虽然看不懂,但是作者做了实验说明了这种方法的有效性,并且比sum等方法优秀!!!
那我只能挖掘了le~
最后:MLP
前面都已经得到了user&item的embeding了,那就已经可以feed到MLP里面进行拟合target rating了~~
下面做的其实也很简单了
也就是在MLP中学习一个matrix,然后再算一下MSE,这些都是比较传统的方法
不过有个不同的地方是在Loss function对一部分进行了Mask,应该是为了防止overfitting的~

Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.

Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.
看到这里也差不多结束了?
其实也还没有~~~
哈哈哈~
刚刚计算Loss的时候你是否想过正则化项的问题?
- Adjacent rating regularization
相邻评级规则化我们的GNN中使用的R-GCN层(1)对于不同的评级类型有不同的参数Wr。这里的一个缺点是它没有考虑评级的大小。
例如,MovieLens中的分级为4和5都表示用户喜欢该电影,而分级为1表示用户不喜欢该电影。理想情况下,我们希望我们的模型能够意识到这样一个事实,即评级为4比1更类似于5。然而,在RGCN中,评级1、4和5仅被视为三种独立的边缘类型–评级的量级和阶数信息完全丢失。为了解决这一问题,我们提出了一种相邻评级正则化(ARR)技术,该技术鼓励彼此相邻的评级具有相似的参数矩阵。假设R中的额定值为r1,r2,r | r |表示用户对项目的偏好越来越高。然后,ARR正则化器是:

Ref: Zhang, M., & Chen, Y. (2019). Inductive matrix completion based on graph neural networks. arXiv preprint arXiv:1904.12058.

编辑
图片来源于互联网
L_ARR究竟在干嘛?
其实很简单!
我们的目的是让相邻的W_r相差尽可能小! 因为我们在计算Loss时,越趋近0,效果越佳~
观察Frobenius范数,可以知道,它的值一定是>=0的,请求只是在相邻层之间进行,那么当Frobenius范数越小时,对Loss的影响就不大~~
到这里终于讲完了~~
感谢你能阅读到这,欢迎交流,共同进步~