CogDL通过引入GRB包,扩展了图机器学习(GML,Graph Machine Learning)对抗攻击与防御模块,现在可以使用CogDL库在多个数据集上进行 GML 对抗鲁棒性的研究。
1. GRB介绍
GRB(Graph Robustness Benchmark)是一个图鲁棒性基准库,在图机器学习模型的对抗鲁棒性上提供可扩展、统一、模块化和可复现的评估,其中包含精心设计的数据集、统一的评估流水线、模块化的编码框架与可复现的排行榜。代码见于 GitHub - THUDM/grb,paper见于 Graph Robustness Benchmark: Benchmarking the Adversarial Robustness of Graph Machine Learning。
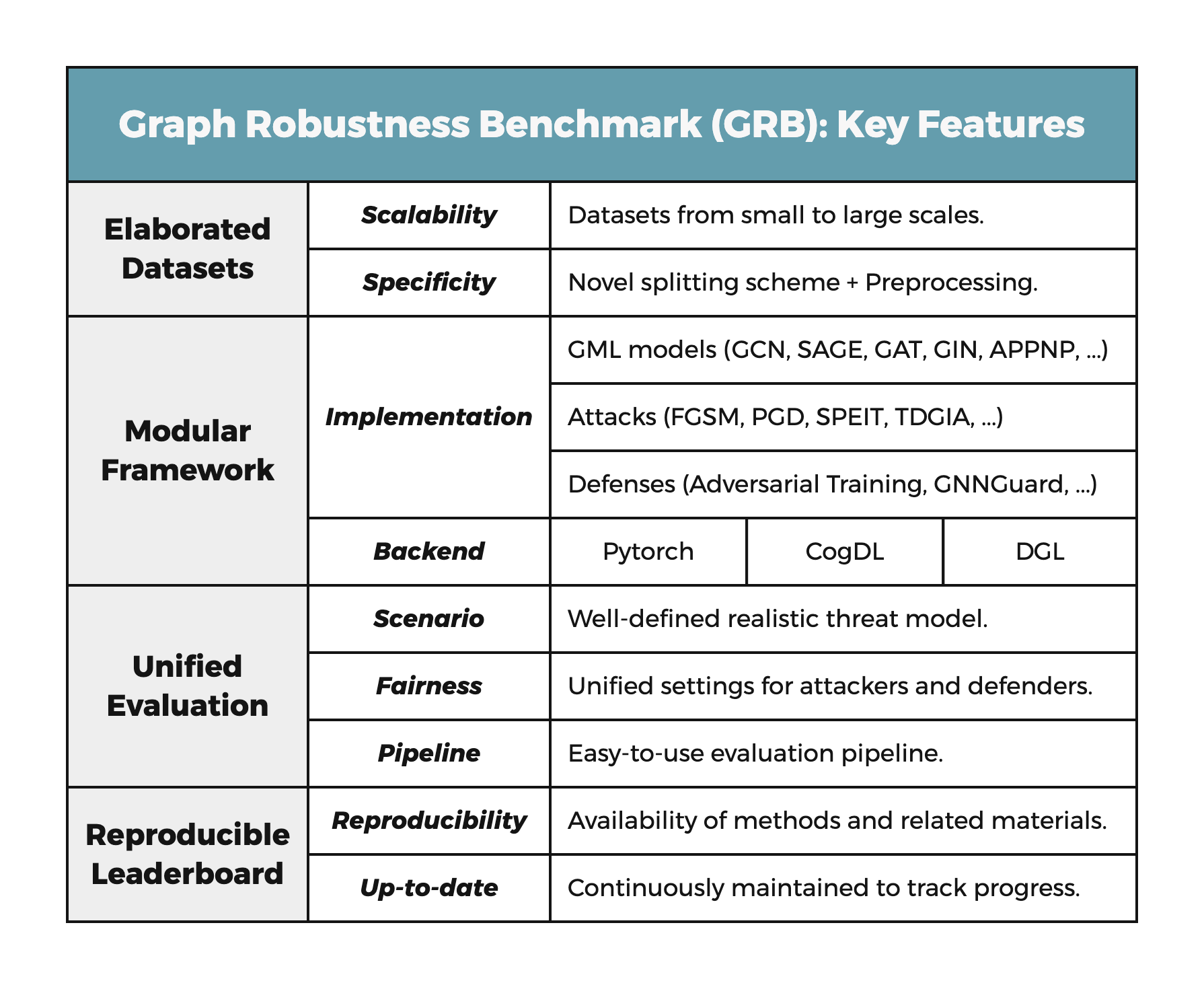
图机器学习(GML)对抗鲁棒性的统一评估场景
为了更好地评估对抗鲁棒性,了解潜在攻击者的能力很有必要,我们可以将攻击按照不同的方面进行分类:
-
知识
- 黑盒攻击:攻击者无法获取目标模型的信息(包括它的结构、参数、防御策略等),但是攻击者可以获取到图数据(结构、特征、训练数据标签等),此外,攻击者可以通过有限地查询目标模型来获得模型的输出。
- 白盒攻击:攻击者可以获取目标模型的所有信息,但当目标模型含有随机的过程时,运行时的随机性仍然会被保留。
-
目标
- 毒化攻击:攻击者生成污染后的图数据,并假设目标模型在这些数据上进行了(重新)训练从而得到更差的模型。
- 规避攻击:目标模型已经训练好了,攻击者生成污染后的图数据来影响目标模型的输出。
-
方法
- 修改攻击:攻击者通过添加/删除边或扰动节点特征来修改原始图(防御者用于训练的图)。
- 注入攻击:攻击者不会修改原始图,而是注入新的恶意节点来影响一组目标节点。
在实践中,最常见的实际情况是 GML 模型已经针对特定任务进行了训练并以秘密方式部署,即攻击的类型是黑盒攻击和规避攻击,因此,GRB 只考虑特定的图机器学习对抗鲁棒性的评估场景——黑盒攻击、归纳学习、躲避攻击。
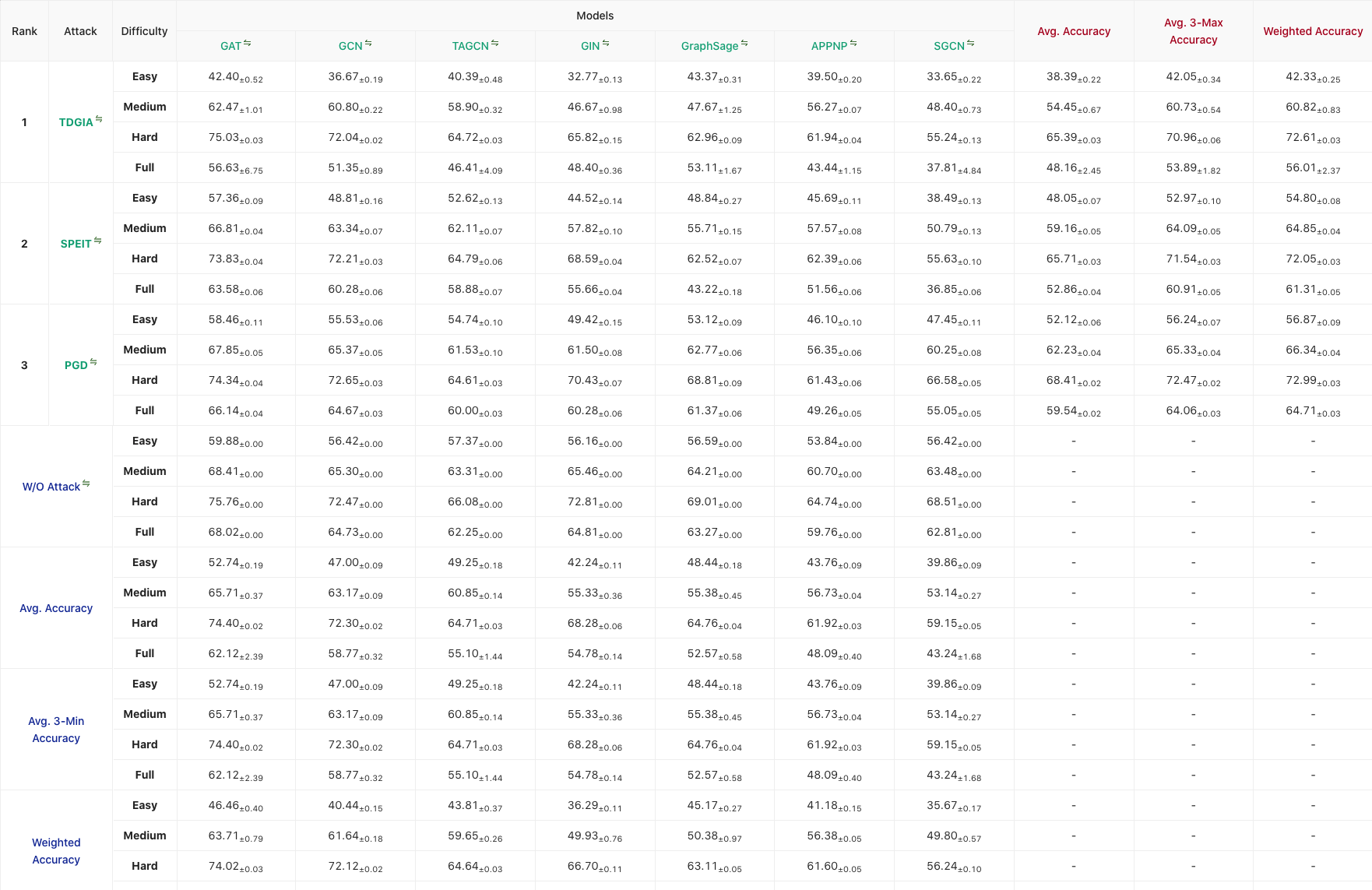
LeaderBoards
GRB维护了在不同数据集上不同攻击与防御效果的排行榜——GRB Leaderboard,下图展示了在 aminer 数据集上 3 种攻击在 7 种 GNN 模型上的效果。
2. 使用方法
CogDL现已将GRB的数据集、攻击与防御模块整合进来,也就是说,可以利用CogDL进行图对抗领域的研究了。下面介绍如何在CogDL中进行图网络的攻击与防御。
1. 攻击
详细的使用方法见于:modification attack,injection attack。
下面以injection attack为例,简要介绍攻击的整个流程。
1) 首先,加载数据集,并获得有关图结构、需要测试的数据。
from cogdl.datasets.grb_data import Cora_GRBDataset
dataset = Cora_GRBDataset()
graph = copy.deepcopy(dataset.get(0))
device = "cuda:0"
graph.to(device)
test_mask = graph.test_mask
2) 训练替代模型
from cogdl.models.nn import GCN
from cogdl.trainer import Trainer
from cogdl.wrappers import fetch_model_wrapper, fetch_data_wrapper
import torch
model = GCN(
in_feats=graph.num_features,
hidden_size=64,
out_feats=graph.num_classes,
num_layers=2,
dropout=0.5,
activation=None
)
mw_class = fetch_model_wrapper("node_classification_mw")
dw_class = fetch_data_wrapper("node_classification_dw")
optimizer_cfg = dict(
lr=0.01,
weight_decay=0
)
model_wrapper = mw_class(model, optimizer_cfg)
dataset_wrapper = dw_class(dataset)
trainer = Trainer(epochs=2000,
early_stopping=True,
patience=500,
cpu=device=="cpu",
device_ids=[0])
trainer.run(model_wrapper, dataset_wrapper)
# load best model
model.load_state_dict(torch.load("./checkpoints/model.pt"), False)
model.to(device)
3) 训练目标模型
model_target = GCN(
in_feats=graph.num_features,
hidden_size=64,
out_feats=graph.num_classes,
num_layers=3,
dropout=0.5,
activation="relu"
)
mw_class = fetch_model_wrapper("node_classification_mw")
dw_class = fetch_data_wrapper("node_classification_dw")
optimizer_cfg = dict(
lr=0.01,
weight_decay=0
)
model_wrapper = mw_class(model_target, optimizer_cfg)
dataset_wrapper = dw_class(dataset)
trainer = Trainer(epochs=2000,
early_stopping=True,
patience=500,
cpu=device=="cpu",
device_ids=[0])
trainer.run(model_wrapper, dataset_wrapper)
# load best model
model_target.load_state_dict(torch.load("./checkpoints/model.pt"), False)
model_target.to(device)
4)引入对抗攻击
# FGSM attack
from cogdl.attack.injection import FGSM
from cogdl.utils.grb_utils import GCNAdjNorm
attack = FGSM(epsilon=0.01,
n_epoch=1000,
n_inject_max=100,
n_edge_max=200,
feat_lim_min=-1,
feat_lim_max=1,
device=device)
graph_attack = attack.attack(model=model_sur,
graph=graph,
adj_norm_func=GCNAdjNorm)
5)攻击替代模型,并在替代模型与目标模型上进行评估
from cogdl.utils.grb_utils import evaluate
test_score = evaluate(model,
graph,
mask=test_mask,
device=device)
print("Test score before attack for surrogate model: {:.4f}.".format(test_score))
test_score = evaluate(model,
graph_attack,
mask=test_mask,
device=device)
print("After attack, test score of surrogate model: {:.4f}".format(test_score))
test_score = evaluate(model_target,
graph,
mask=test_mask,
device=device)
print("Test score before attack for target model: {:.4f}.".format(test_score))
test_score = evaluate(model_target,
graph_attack,
mask=test_mask,
device=device)
print("After attack, test score of target model: {:.4f}".format(test_score))
2. 防御
CogDL提供了已经实现好的防御模型(GCNSVD、GNNGuard、GATGuard、GCNGuard、RobustGCN),可以像普通模型一样引入训练。同时,CogDL实现了经典的防御方法——鲁棒性训练,只需要在 Trainer 中传入 atatck 与 attack_mode 参数即可。
1)防御模型
详细的使用方法见于:defense model。
从 cogdl.models.defense 导入防御模型。
# defnese model: GATGuard
from cogdl.models.defense import GATGuard
model = GATGuard(in_feats=graph.num_features,
hidden_size=64,
out_feats=graph.num_classes,
num_layers=3,
activation="relu",
num_heads=4,
drop=True)
print(model)
2)鲁棒性训练
详细的使用方法见于:adversarial training。
定义攻击方法,并在在 Trainer 中传入 atatck 与 attack_mode 参数,进行鲁棒性训练。
model = GCN(
in_feats=graph.num_features,
hidden_size=64,
out_feats=graph.num_classes,
num_layers=3,
dropout=0.5,
activation=None,
norm="layernorm"
)
from cogdl.attack.injection import FGSM
attack = FGSM(epsilon=0.01,
n_epoch=10,
n_inject_max=10,
n_edge_max=20,
feat_lim_min=-1,
feat_lim_max=1,
device=device,
verbose=False)
mw_class = fetch_model_wrapper("node_classification_mw")
dw_class = fetch_data_wrapper("node_classification_dw")
optimizer_cfg = dict(
lr=0.01,
weight_decay=0
)
model_wrapper = mw_class(model_target, optimizer_cfg)
dataset_wrapper = dw_class(dataset)
# add argument of attack and attack_mode for adversarial training
trainer = Trainer(epochs=200,
early_stopping=True,
patience=50,
cpu=device=="cpu",
attack=attack, # 增加 attack 参数
attack_mode="injection", # 增加 attack_mode 参数
device_ids=[0])
trainer.run(model_wrapper, dataset_wrapper)
model.load_state_dict(torch.load("./checkpoints/model.pt"), False)
model.to(device)
在选择防御方法后,我们可以使用上述攻击的流程,对防御模型进行攻击与评价,评估防御模型的效果。