论文链接:https://arxiv.org/pdf/2112.02936.pdf
代码仓库:GitHub - zhitao-wang/PLNLP: Pairwise learning neural link prediction for ogb link prediction
Background:
- 传统启发式方法在处理不同类型的网络时往往具有较差的适用性和表达能力,归因于其形式简单且邻域信息手工收集,需要大量先验信息以及试错。
- 现存神经网络链接预测方法太过注重设计表达能力强的神经网络结构,忽视了很多基本的属性。
- 仅仅将Link Prediction问题视为link二分类问题并采用交叉熵来计算损失尤为偏颇。在正负样本极度不均匀的情况下难以给出明确的分类标签。
Contribution:
- 作者提出了有效的成对学习神经链接预测Pairwise Learning Neural Link Prediction (PLNLP) 。该框架将链路预测视为排名问题,由邻域编码器、链路预测器、负采样器和目标函数四个主要组件组成。
- 对于链接预测器,作者设计了不同的评分函数,可以根据不同类型的图结构进行选择。在负采样器中,作者提供了几种特定于问题的采样策略。至于目标函数,作者建议使用有效排名损失,这近似最大化了标准排名指标AUC。
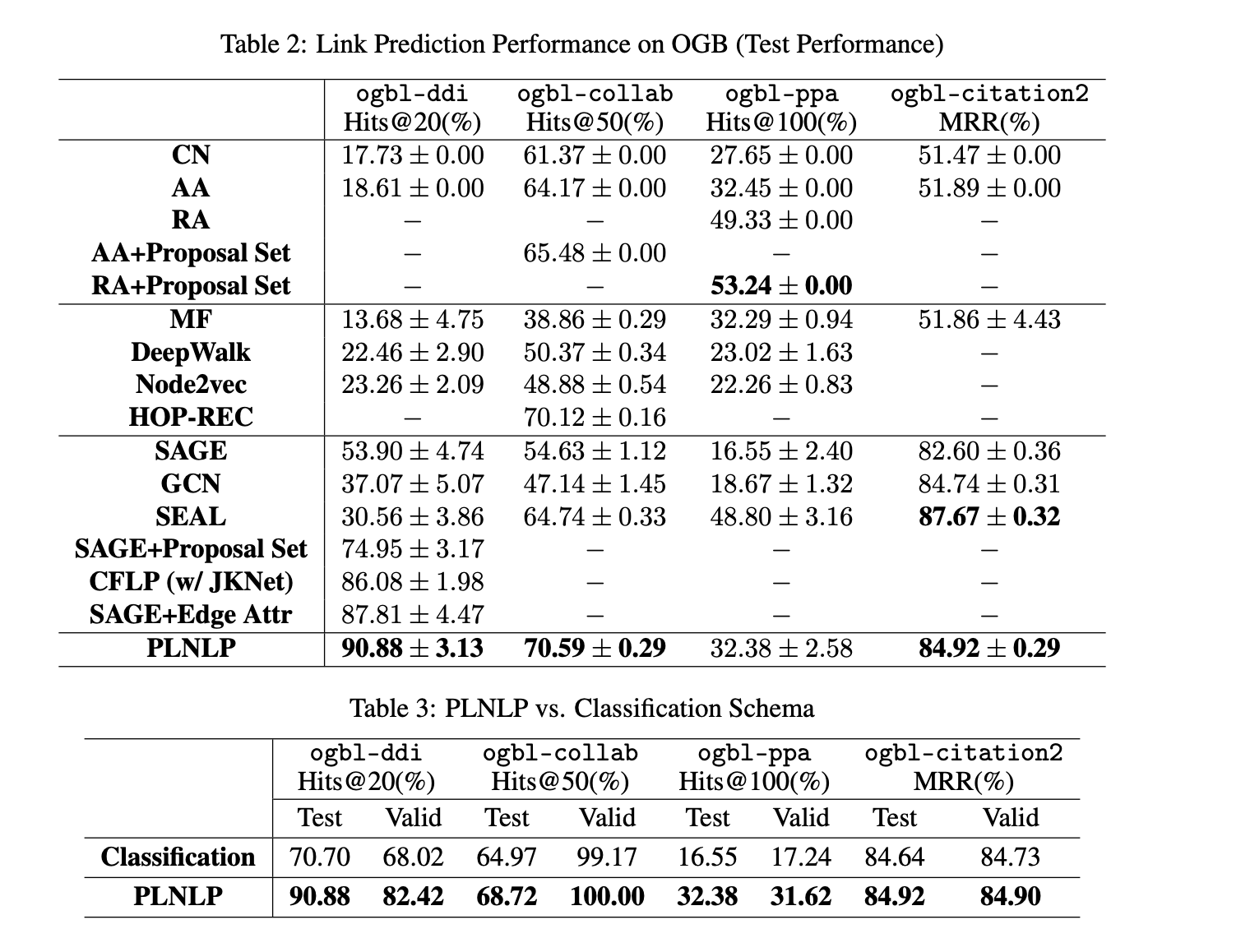
- 在Open Graph Benchmark (OGB)四大链接预测数据集中包括ogbl-ddi和ogbl-collab,ogbl-ppa和ogbl-ciation2分别实现了第一和第二名的成绩。进一步验证了PLNLP的有效性。
PLNLP Framework
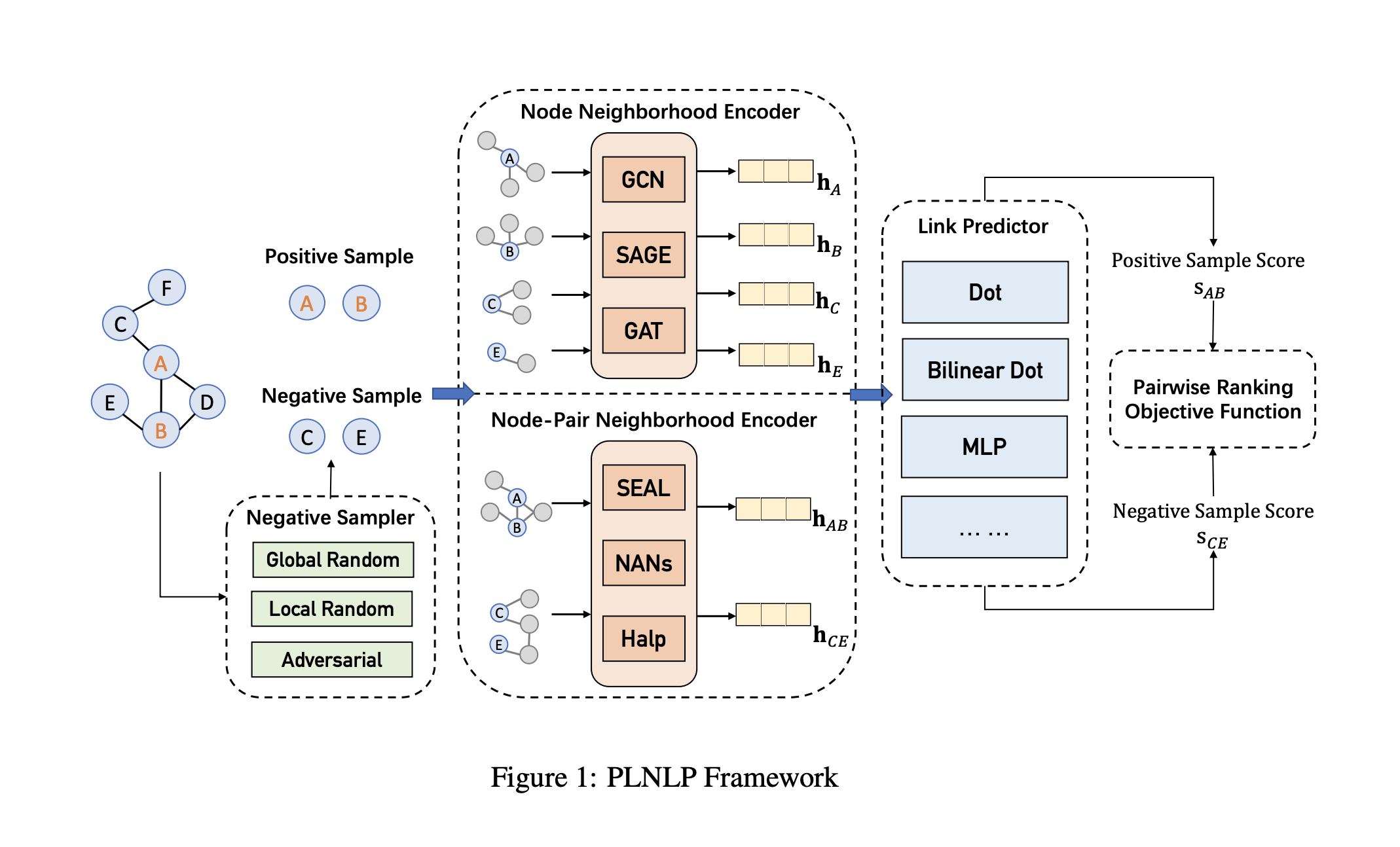
Neighborhood Encoder–邻域编码器
作者提出采用邻域神经编码器来提取输入样本的结构信息,主要考虑两种类型的邻域编码器。第一种是节点邻域编码器Node Neighborhood Encoder (NNE)它将输入样本的两个节点与其自己的邻域分别编码为两个隐藏表示。任意的通用图神经网络如GCN,GAT,GraphSAGE均可作为NNE。假设输入样本 其编码过程表示为:
其中 通常表示节点
的输入特征或嵌入向量。在此框架中只考虑同构图,因此意味着所有节点可以共享一个NNE。
另一种邻域编码器是边层面的Edge level Neighborhood Encoder (ENE)或称之为节点对邻域编码器来捕获邻域之间的结构相互作用。假设输入节点对 ,ENE获取其隐藏表示如下:
Link Score Predictor–链路预测器
在节点级别或节点对(边缘)级别获得隐藏表示 和
后,框架将计算输入样本的链接分数。作者提供了评分函数的几种选择。
- Dot Predictor:
- Bilinear Dot Predictor:点运算符由于其可交换属性,只能用于无向图。对于有向图,我们可以采用双线性点运算符来使评分函数不交换,其中
是可学习矩阵。
- MLP Predictor:多层感知机预测器
如果使用 NNE 来获取隐藏的表示,则 MLP 的输入有几种可能的形式。如果图是无向的,可以采用广泛使用的交换算子,即hadamard乘积
。若图有向的,则可以使用级联运算符
Negative Sampling–负采样器
通常而言,真正的非链接集合 E − 在训练数据中不可用。传统的策略是随机抽样负节点对(v k,v j),它具有未知的链接状态,并被假定为负样本。对于不同的问题或图表类型,我们可能有不同的抽样策略。主要有Global Sampling,local Sampling,Adversarial Sampling and Negative Sample Sharing
作者在文章中提出了三种负采样策略。
- Global Sampling. 全局抽样表示对于每个正样本,我们均匀抽样集合中的负节点对。这种策略适用于求解全局排名的问题。
2.local Sampling. 局部采样表示,我们首先选定一个锚点,对于这个锚点全局采样负节点对,这种策略适合于寻找单一节点的排名,例如推荐系统中向某一用户推荐商品。
3.Adversarial Sampling. 不同于真实采样,作者设计了一个生成模型产生高质量的负样本,目的是使预测任务更加困难。这样,链接预测模型和负样本生成器就展开了一场对抗性博弈。
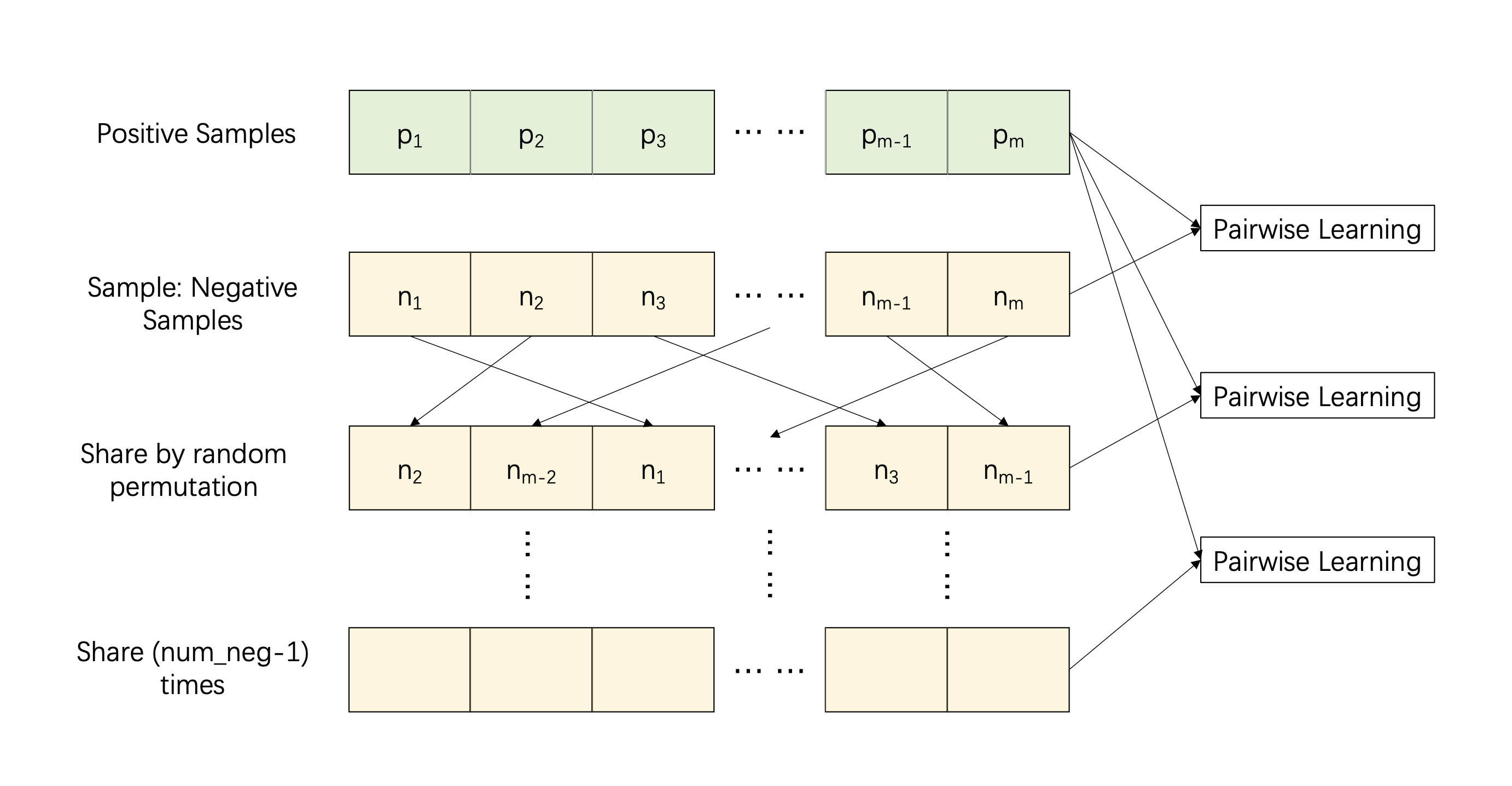
4.Negative Sample Sharing. 如图所示,假设正样本总数为m,我们首先抽取m个负样本,构造m个指标相同的训练对。给定负样本,共享机制将随机排列负样本的指标,形成m个新的训练对。
Pairwise Learning with Ranking Objective
由于网络的稀疏性,链接对和非链接对之间经常存在极端不平衡。同时,大多数链接预测任务的目标不是将正对标记为 1,而将负对标记为 0,而是要求将正对的排名高于负对。为了与链接预测的总体目标保持一致,我们采用排名思想来进行模型的学习,可以表示为:
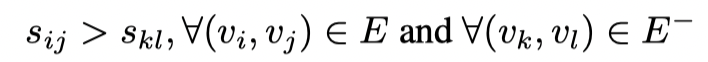
其中 为链接预测器的输出,
是真正的非链接对的集合。实际上,上述学习目标等效于曲线下面积 (AUC) 最大化,该面积被解释为正样本排名高于负样本的概率。AUC 值定义如下:
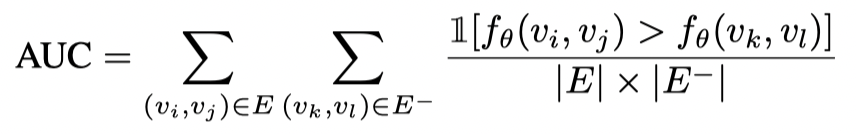
其中1[·]表示示性函数,当其中不等式成立时取值为1否则为0。本文中作者选用最小代理损失的平方作为损失函数,其框架可以灵活地采用接近 AUC 的任何其他代理函数。基本 AUC 优化目标函数定义如下:
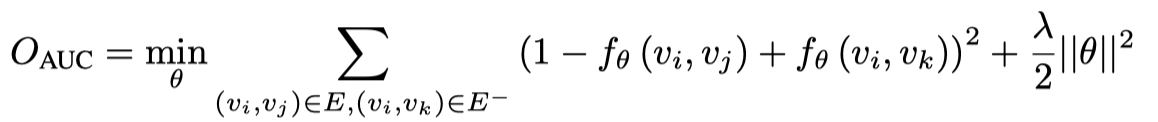
上述函数强制正样本和负样本之间的边距为 1。在某些情况下,此约束对于优化来说过于严格。通过将铰链损耗与上述功能相结合,可以放松它:
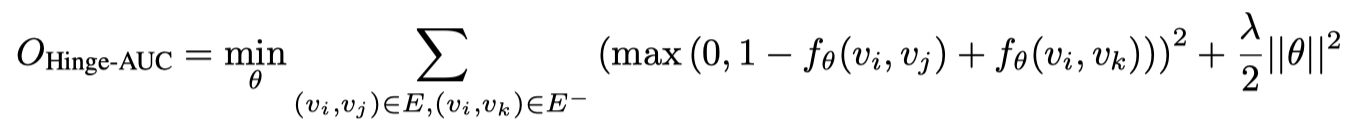
上述函数仅强制正样本和负样本之间的边距大于 1。此外,如果预计对训练边(正样本)上的权重进行建模,则边距可能不会固定为 1。介绍样品权重的简单方法如下:
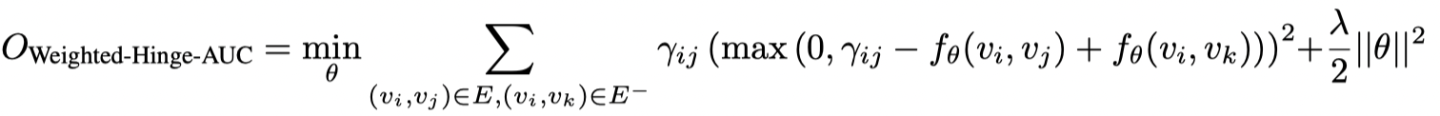
是自适应的边距,它可能对应于训练边的归一化权重。在上述目标函数中,为了防止过拟合问题,作者对权重为 λ 的参数使用 L2 正则化。在给定一个正对 (v i, v j) 和一个采样负对 (v k, v l),模型的参数 θ 通过随机梯度下降 (SGD) 方法进行优化。在大多数情况下,我们使用第一个方程中的基本目标函数。当考虑sample权重时时,使用第三个方程的目标函数。
Experiments:
实验部分主要为PLNLP在Open Graph Benchmark (OGB) data的四个数据集上链接预测任务的表现,baseline选有传统邻居相似度考量的CN,AA,RA和图上随机游走及其扩展方法,有S图表示学习方法SAGE,图卷积网络GCN等。采用Mean Reciprocal Rank (MRR)作为评价指标。
此外,作者将PLNLP与通用分类学习框架进行了比较,其中损失函数是交叉熵的。在这项消融实验中,作者在两个框架中保持相同的神经结构(相同的编码器)。对于所有数据集,我们使用最基本的AUC目标函数,并且在这项研究中不使用随机游走增强来表示ogbl-collab。为了保证公平性,我们使用相同的负采样策略,并使用相同数量的负样本。结果示于表3中。结果表明, PLNLP在链接预测问题上的表现显著优于通用分类学习模式, 表明所提出的成对学习可以最大限度地提高图神经模型的性能。
参考资料
[链接预测]“Pairwise Learning” from腾讯团队OGB:【链接预测】“Pairwise Learning” from腾讯团队OGB - 知乎