论文链接:https://ogb.stanford.edu/paper/kddcup2021/mag240m_Academic.pdf
代码仓库:deepmind-research/ogb_lsc/mag at master · deepmind/deepmind-research · GitHub
Abstract
有效且⾼效地⼤规模部署图神经⽹络 (GNN) 仍然是图表⽰学习中最具挑战性的⽅⾯之⼀。许多强⼤的解决⽅案仅在相对较⼩的数据集上得到验证,通常会产⽣违反直觉的结果。开放图基准⼤规模挑战(OGB-LSC)最近打破了这一障碍。DeepMind团队参加了OGB-LSC的两个赛道:一是自建的深度节点分类器,二是超深(50层+)加去噪目标的推理图回归器。这两个方法分别在MAG240M和PCQM4M榜单上达到了top3效果。本文将重点介绍DeepMind团队基于图自监督表征学习的节点分类方法。
Introduction
相应的图表示学习在工业和学术界已经取得了巨大成功,GNN被成功用于药物筛选,建模玻璃力学,社交网络推荐和芯片设计等不同领域。
虽然上述结果令人印象深刻,但它们可能只是触及了经过良好调教的GNN 模型的表面。许多真实世界问题需要规模化图表示,要么是图数量大,要么是图规模大。可能最清楚的动机来源于Transformer系列模型。Transformer在大图上应用自注意力机制,可以被当做是GNN的一个特例。自然语言领域已经展示了Transformers规模化后带来的收益,例如GPT-3。Transformers享有优秀的灵活属性,代价是复杂机制:每个节点更新需要依赖邻居节点特征加权求和。对比之下,GNNs依赖消息传递,通过边传递向量信号训练发送和接收节点,按经验说这是一个解决需要复杂推理或模拟问题的好方法。
基于更普适的消息传递的GNNs还未像Transformer大规模应用的一个原因是缺少合适的数据集。直到最近才从基于几千个节点的简单转导基准过渡到基于现实世界大规模综合基准,但是仍有重大的问题。例如,在很多任务上,基于随机初始化或浅层GNN或单标签启发传播GNN可以以一个很小部分的参数达到或接近SOTA效果。当最前沿的方法都无法解决这些问题,这就经常成为社区中最受争议的讨论。一个常见例子是:我们是否需要更深度的更有表达能力的GNNs?
深度学习的研究突破已经给有影响的大数据集竞赛带了个好头,对图像识别领域,最有名的例子就是ImageNet大规模视觉识别挑战(ILSVRC) 。事实上,真正的深度学习革命,从2012年AlexNet CNN模型在ILSVRC 2012取得成功就开始了,这坚实奠定了深度CNN在后续几十年作为图像识别领域的驱动力。
相应的,DeepMind团队进入了近期提出的OGB-LSC比赛,他以前所未有的量级提供了图表示学习任务,百万级节点,十亿级边,以及百万级别的图。而且,任务是从意识中即时可行的关联设计而来,而且被验证了使用显式GNN来解决是非常必要的。可以说,这些超大数据集为超深GNN网络效果,以及从0搭建自监督GNN提供了一个很好的展示平台。这样,DeepMind团队为下述讨论提供了一个有价值的正向结论的证据:深度可表达GNN对于特定复杂度的问题是十分有必要的。
Dataset Description
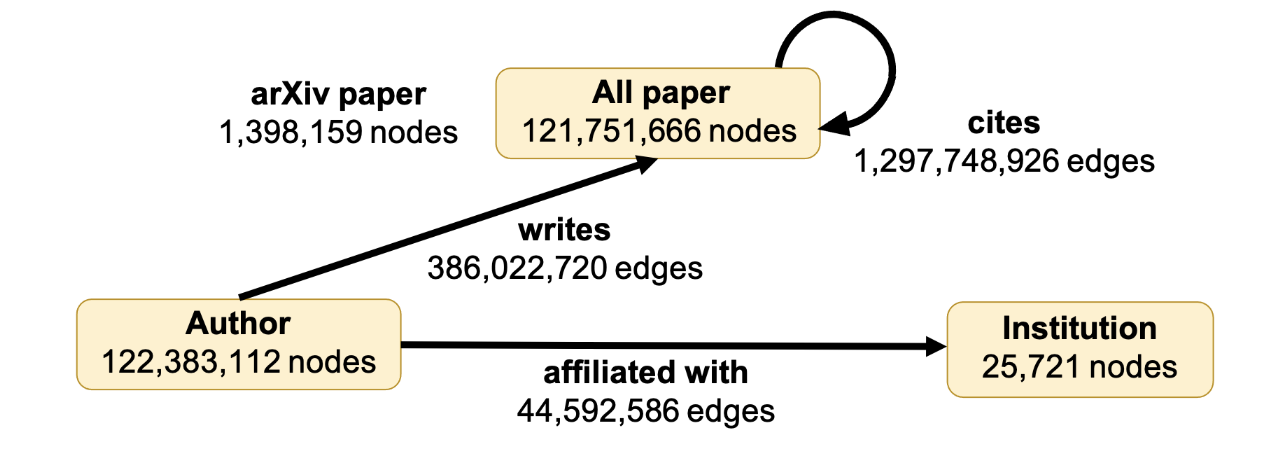
MAG240M-LSC是一个直推式节点分类数据集,是基于微软学术图(MAG),这是一个包含论文、作者和机构节点异构图,边包含了之间的关系,论文间的引用,作者写作的论文,作者挂靠的机构。所有论文节点被赋予768维输入向量,是根据标题和摘要抽取的RoBERTa句向量。MAG240M是当前最大规模公开的节点分类数据集,约2.4亿节点,18亿边。目的是把140万arXiv论文分类到相应主题内,根据一个时间分割,18年前的作为训练,19和20年的分别作为验证和测试集合。
Model Architecture
对于上述任务,DeepMind团队使用了一个通用的编码-处理-解码的架构。这意味这输入数据会使用节点、边、图维度编码器编码到隐向量空间,而隐向量特征也会被合适的解码函数解码到对应层级预测结果。中间计算过程的主体是一个处理器网络,来针对编码隐向量执行多种图神经网络层级的计算。
来形式化表达的话,假设我们的图是 \mathcal{G}=(\mathcal{V}, \mathcal{E}), 有节点特征 \mathbf{x}_{u} \in \mathbb{R}^{n}, 边特征 \mathbf{x}_{u v} \in \mathbb{R}^{m} 以及图级别的特征 \mathbf{x}_{\mathcal{G}} \in \mathbb{R}^{l}, 对于节点 u, v \in \mathcal{V} 以及边 (u, v) \in \mathcal{E}. 编码函数为 f_{n}: \mathbb{R}^{n} \rightarrow \mathbb{R}^{k}, f_{e}: \mathbb{R}^{m} \rightarrow \mathbb{R}^{k} and f_{g}: \mathbb{R}^{l} \rightarrow \mathbb{R}^{k} 然后转化这些输入到隐空间:
我们的处理器网络对于这些隐向量执行多轮消息传递:
其中 \mathbf{H}^{(t)}=\left(\left\{\mathbf{h}_{u}^{(t)}\right\}_{u \in \mathcal{V}},\left\{\mathbf{h}_{u v}^{(t)}\right\}_{(u, v) \in \mathcal{E}}, \mathbf{h}_{\mathcal{G}}^{(t)}\right) 包含t步骤全部隐向量 t \geq 0.
处理器网络 P 会被迭代 T 步, 重建最后的隐层表示 \mathbf{H}^{(T)}. 这些可以被解码为节点级,边级,以及图级别的预测, 使用这些解码器函数 g_{n}, g_{e} and g_{g} :
我们在后面章节会详细阐述f , P和g的具体设计,大致而言,f和g是简单的MLPs,然而为P使用了高度表达力的GNN,目的是最大化大规模数据集的优势。具体的,使用了消息传递神经网络(MPNNs)和图网络(GNNs)。
MAG240M-LSC
降采样 - 在比MAG240M数据集小很多的数据集上运行图神经网络已经很容易遇到一些尺寸过大问题,非常必要使用降采样、图分块、更轻量级GNN架构。
因为我们很希望放大有表达能力的GNN的作用,并且使得任意分组间都可以传递消息,所以我们优化了降采样方案。相应的,我们针对要计算隐向量的节点周围采样适量尺寸的节点,在他们上运行GNN模型,并且使用中间节点的隐向量来训练和评估模型。
我们采用了标准的GraphSAGE降采样策略,并且在这上面做了一些修改来适应MAG240M数据集的特点,如下:
1、我们针对不同边类型,执行了独立流程的降采样流程。例如,一个作者节点会独立采样一个预先指定数量的这个作者撰写的论文,以及预先指定数量的该作者挂靠机构。
2、GraphSAGE针对所有节点都抽取一个固定数量的邻居节点,用放回采样来实现,即便每个节点的邻居的数量是不同的。我们发现这对邻居少的节点很浪费,因此我们把预先指定的邻居数量作为上限,例如K,u节点的原始邻居表示为Nu ,我们这么处理:
-
对于某类型节点少于K个邻居的情况 (|N| ≤ K) ,我们就把所有邻居纳入计算,不做采样。
-
对于有适度邻居的节点(K < |N| ≤ 5K) ,我们使用非放回采样,在内存消耗可接受情况下避免重复节点。
-
对于其他节点(|N| > 5K) ,我们复用原始的GraphSAGE采样策略,放回采样K个邻居,这样不需要对邻接矩阵做一次额外的行拷贝。
3、GraphSAGE将采样后的节点指向采样它的节点,并且为他们运行跟深度相同步数的GNN。我们取而代之修改了消息传递更新规则来形成灵活的双向边,这样可以使我们可以在这个结构上运行更深的GNN,确切的方式会在后面模型结构部分详述。
考虑这些,我们模型的降采样策略从论文节点作为中心开始,最大深度是2,足以包含了机构节点。我们没有发现采样更深的好处。取而代之,我们比GraphSAGE采样更多分组,来利用许多节点的广度上下文信息。
层级0:选择的中心论文节点。
层级1:采样K=40引用论文,K=40被引用论文,K=20该论文作者。
层级2:我们根据下述策略采样,对于所有在层级1采样的论文和作者节点:
论文:和层级1的论文采样策略一致。
作者:我们采样K=40写作论文,K=10该作者挂靠机构。
综上,这使得最大尺寸的采样组达到接近10000个节点,接近传统完整图网络大小。加上MAG240M 有上亿个论文节点要采样,我们的配置达到了直推式节点分类模型从未达到过的规模。我们发现这么大的采样组规模对于模型效果确实是有必要的。
针对MAG240M降采样,最后重要的一点是和重复论文节点有关,就是那些有重复RoBERTa向量的论文,这看上去像是一个论文提交到了多个场所(会议、期刊、arXiv等),出于丰富我们采样组的目的,我们通过合并邻接矩阵的行和列,把同一个论文的多个版本合并。
输入预处理 - 如前所述,我们寻找能支持在超大规模采样组上运行GNN的方案。这就给我们模型的计算和存储方面很大压力。相应的,我们发现压缩输入RoBERTa向量是有用的,我们的量化分析发现,使用129维PCA映射已可以囊括其中90%变量。因此我们使用这些PCA向量作为论文的真实输入。
进而,只有论文节点真实提供了特征,我们复用了基线LSC代码来计算作者和机构的特征。对于作者,我们使用这个作者所有论文的PCA特征均值,对于机构,我们使用这个机构挂靠的所有作者的特征均值。通过实验,我们发现这个简单有效的方法表现超过利用结构特征进行计算。这和某些研究有些出入,可能是因为我们使用了更有表达能力的GNN。
输入特征xu除了包含PCA特征,还有这个节点的类型的独热编码(论文、作者或机构),这个节点所在的采样深度(0、1、2),还有位编码的论文发表年份(其他节点置0)。最后,根据越来越多的研究支持使用标签作为直推式节点分类任务的特征,我们把arXiv论文的标签作为特征(其他节点置0)。我们确信验证集标签没有在训练时使用到,并且中间节点的自身标签也没有使用。有可能在2层采样到中心节点,但是如果发生这种情况我们会把标签隐去。
我们也为边赋予了一个边类型特征xuv ,这是个7比特01特征,前三比特表示抽样节点类型(论文、作者、机构),后四比特表示被抽样节点类型(被引用论文、主论文、作者、机构)。我们发现在边特征上运行标准GNN,跟基线对比效果要好于运行异构GNN,可能因为我们的处理器GNN表达能力强。
模型架构 我们在MAG240M上使用的GNN架构是,编码和解码器均是两层MLP,隐层512特征。节点和边编码器输出层计算256特征,我们后面在hu和huv的计算的t步内保持这个维度。
我们处理器网络是一个深度消息传递神经网络(MPNN) 。他计算边间传递的消息向量,然后聚合到接收节点,消息传递操作和更新操作都是两层MLP,有着和编码器相同的隐层和输出尺寸。我们注意到选定的MPNN 的两个特定方面:
1、我们发现使用全局隐向量或者更新边向量没有用。这可能是因为预测过程非常集中于中心节点,因此使用边特征和类型没有编码额外信息。
2、除了池化所有输入消息,我们也池化了一个节点发送的所有消息。并且并联作为一个发送节点的更新函数的输入。这使得我们在不用引入更多性能问题时能模拟双向边,使得我们可以套用深度超过采样深度的MPNN网络。
这个过程重复经过T = 4 的消息传递层,之后中间节点的输出hu 送到解码网络去预测结果。
从头设计的训练目标 在MAG240M 上的非arXiv 论文没有被打上标签,因此在一个标准的节点分类训练机制下,只会作为有标记节点的邻居对训练算法有贡献。早期的自监督图表示网络已经展示了这可能是个浪费的方法,即使在小规模直推数据基准上。合理使用无标签数据,可以给模型提供特征和网络结构信息,这些很难从监督数据内获得。在像MAG240M 这样的无标签数据比带标签数据多120倍的数据集上,我们能获得巨大的提升。
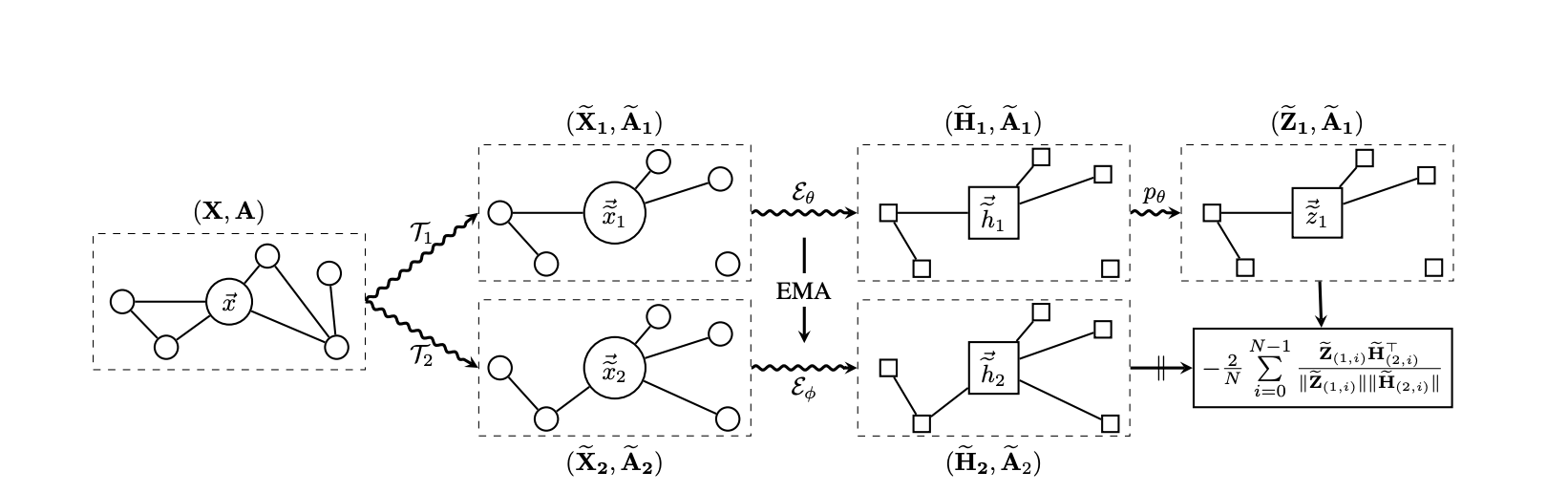
特别的,我们使用BGRL,一种近期提出图上自监督学习的方法。与其从多个视角对比多个节点表示,BGRL从头定制GNN来使得一个节点向量可以预测在另一个目标GNN下的节点向量。目标网络的参数总是设置成GNN的指数移动平均 (EMA) 。
训练和正则化 我们训练GNN的目标是最小化中间标注节点的标签CE误差,加上非标注的中间节点的BGRL目标。我们用AdamW和SGD优化器,参数是 β1 = 0.9, β2 = 0.999 ,系数衰减率λ = 10−5 。我们使用了一个余弦学习率方案,基础学习率η = 0.01 ,50000冷启步骤,在500000次训练后衰减。优化在动态分组数据上进行,我们随机添加样本构造每个训练minibatch,直到如下条件之一满足:超过84000个节点,185000条边,或者256个采样组。
归一化方法,我们在验证集合上针对准确率使用早停方案,并且应用特征dropout(p = 0.3 ),在GNN的每个消息传递层上应用边丢弃(p = 0.25 )。我们进而应用层正则化来调节我们所有的MLP输出。
评估 在评估阶段,我们利用直推式降采样学习方案的优势来加强我们的预测效果:首先,我们确保模型测试时能拿到所有验证数据的标签,因为这个信息很有指导性。而且,我们确保相同版本的节点有一样的标签。因为我们的预测是会潜在适应已经采样好的采样组的结构,对每个测试节点,我们在50个采样组上取平均预测结果,这个内置的小方法持续的提升验证集上的效果。最后,既然我们已经把EMA作为BGRL的目标网络的一部分,对我们的评估集的预测我们使用EMA参数,因为他们会略微更稳定一些。
Result
最终的模型在MAG240M上的验证精度为77.10%。在LSC测试集上翻译后,我们在MAG240M上恢复了75.19%的测试精度。尽管我们使用标签作为输入或验证培训,但我们承担了最小的分发转移,这是对我们原则性集成和后处理策略的证明。
我们的方法证明了深刻的表达图神经网络可以对工业相关性的大规模数据集产生的影响。此外,我们还展示了最近为GNN训练提出的几个辅助目标,如BGRL,如何在正确的数据集尺度上具有高度的影响力。我们希望我们的工作有助于解决社区中的一些公开争议,例如深度gnn的效用,以及在这种环境下自我监督的影响。
在很多方面,OGB对图形表示的学习就像ImageNet对计算机视觉的学习一样。我们希望OGB- lsc只是推动GNN架构研究向前发展的一系列活动中的第一个,并真诚地感谢OGB团队的辛勤工作和努力。