论文链接:https://dl.acm.org/doi/10.1145/3485447.3511986
This paper proposes PaSca, a new paradigm and system that offers a principled approach to systemically construct and explore the design space for scalable GNNs
本文提出了一种新的范式——PaSca 为可扩展的gnn提供系统构建和探索设计空间的原则性方法
we implement an auto-search engine that can automatically search well-performing and scalable GNN architectures
自动搜索性能良好和可扩展的GNN架构
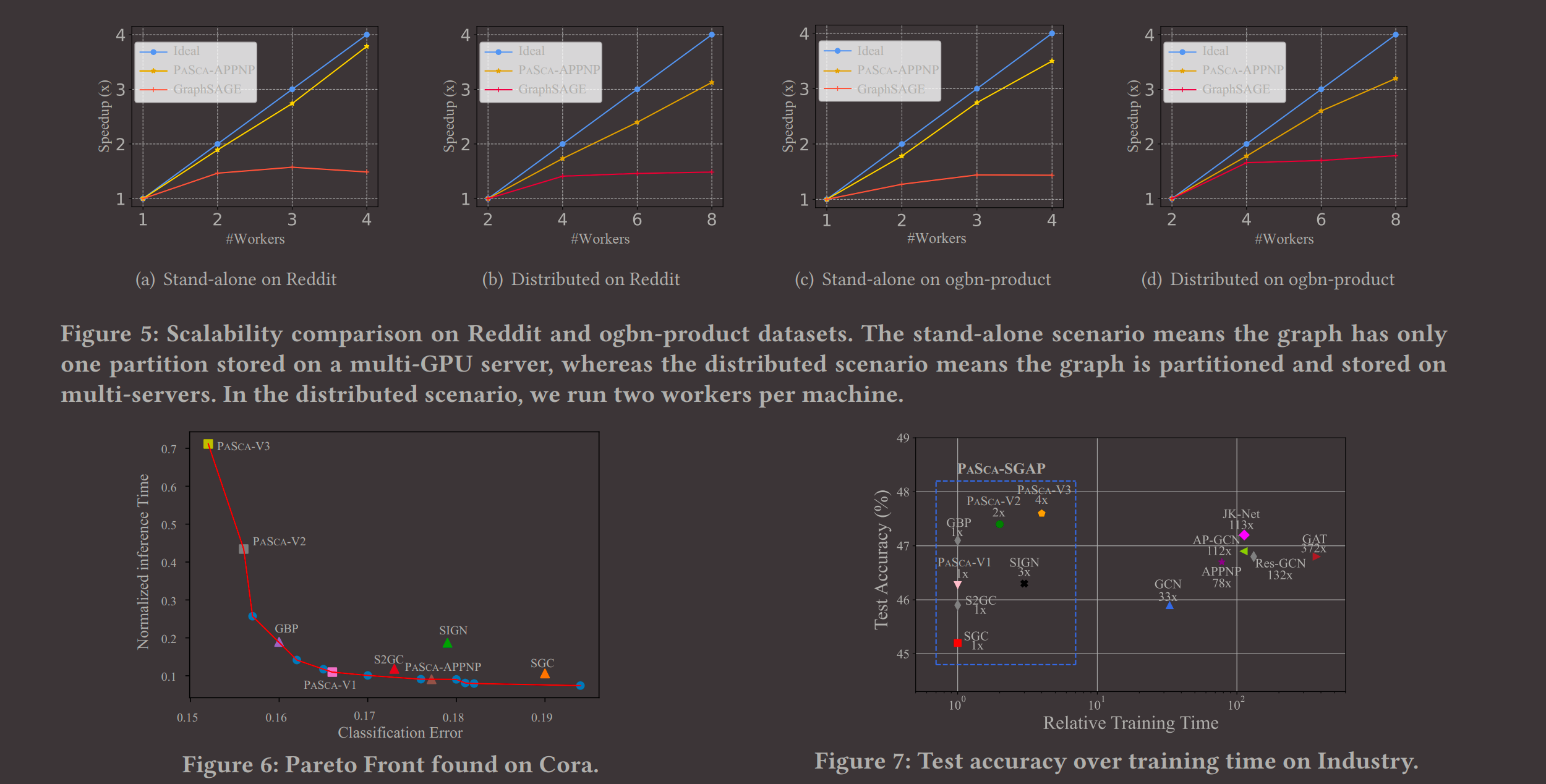
打败了JK-Net,0.4个百分点,速度有一定提升
大多数的GNN需要perform a recursive neighborhood expansion to gather neural messages repeatedly,这个过程会造成指数增长的资源消耗,是目前大规模GNN计算面临的主要问题之一。
To demonstrate this issue, we utilize distributed training functions provided by DGL [2] to execute the train pipeline of GraphSAGE
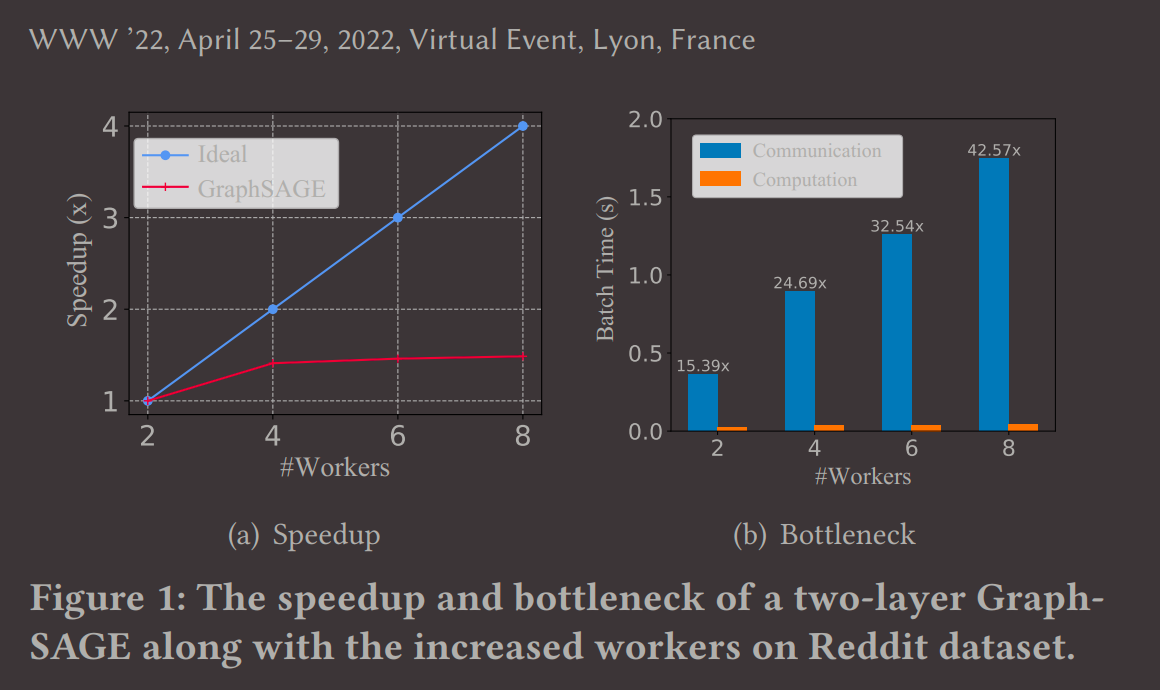
(加速效果)
由此我们提出了一个新系统:Pasca,有以下特点:
- Scalable Paradigm
- Auto-search Engines.:
Concretely, the representatives (i.e.,PaSca-V2 and PaSca-V3) outperform the state-of-the-art JK-Net by0.2% and 0.4% in predictive accuracy on our industry dataset, while achieving up to 56.6× and 28.3× training speedups, respectively.
- Relevance to Web.
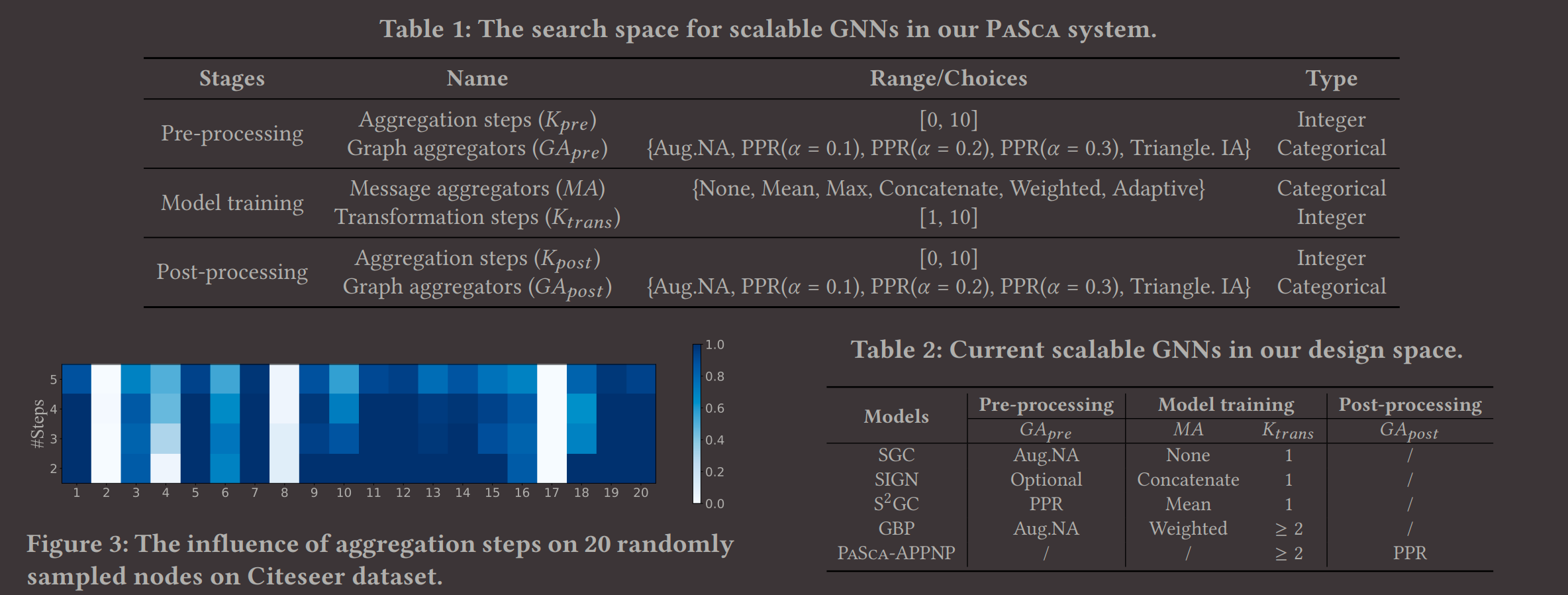
系统内的几个设计:
(本人数学不好,可以去文章里看一下公式)
- GNN Pipelines.
- Scalable GNN Instances.
- Graph Neural Architecture Search.
提出了一个SGAP(Scalable Graph Neural Architecture Paradigm)范式:
it differs from the previous NMP and DNMP framework in terms of message type, message scale, and pipeline:
- Pre-processing.
- Model-training.
- Post-processing.
Search Engine:
系统搜索引擎结构:
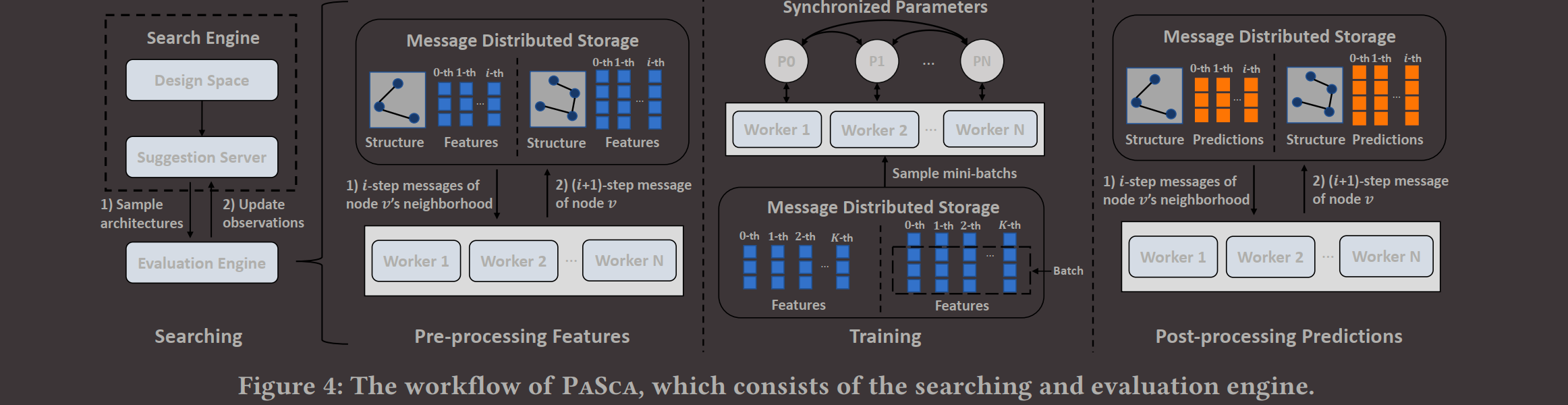
Evaluation Engine:
- Graph Data Aggregator.
- Neural Architecture Trainer.
最后是实验效果: