论文题目:
GNN is a counter? Revisiting GNN for question answering
论文链接:
https://openreview.net/pdf?id=hzmQ4wOnSb
在QA任务中,为了使QA系统具备人类水平的推理能力,现有研究通常会使用预训练语言模型(LMs),结合精心构造的图神经网络(GNNs)模块来进行知识图谱(KGs)的推理。然而,这些GNN模块是否真的能够模拟复杂的推理过程?为了打开GNN的黑匣子,我们剖析了现有使用GNN的问答方法,发现即使是一个非常简单的graph neural counter也能够获得很好的效果。
1 背景
对于问题相关知识的查找和推理是KBQA的关键,其知识来源主要有两个方面:1)隐式编码在预训练语言模型中;2)显示存储在知识图谱(KGs)中。相比之下,预训练语言模型在结构化推理方面存在一定困难,而知识图谱则效果更好,因为它保留了特定的信息和关系,并且经常能产生可解释的结果,比如reasoning chains。
为了综合这两点,有许多将大规模预训练模型和图神经网络结合的工作,取得了不错的效果。这些方法在处理KG中通常遵循两步:1)抽取schema graph,即检索KG中与问题相关的KG子图,并获得节点表示和边的表示;2)图上推理,通常通过一些复杂的图神经网络得到优化的节点表示。
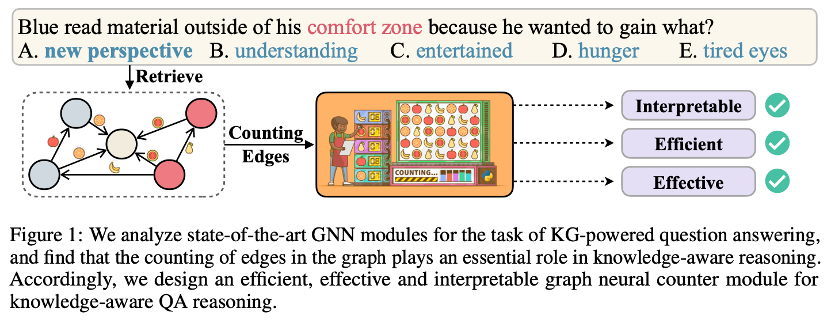
2 研究方法
对于QA系统来说,这些GNN模块是不够复杂还是过于复杂?它们在推理中是怎么发挥作用的?为了回答这些问题,我们采用Sparse Variational Dropout (SparseVD) 对 GNN 的网络结构进行分析。SparseVD原先用于模型压缩,能够作为一个指标,计算出在不损失模型精度的条件下,模型哪一部分可以被修剪。我们通过sparse ratio值来衡量GNN网络结构中各个模块对于推理的贡献。
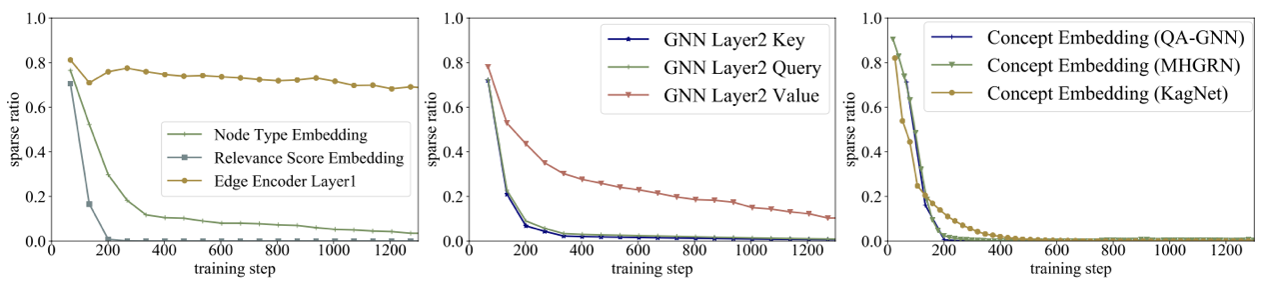
从一图可以看出,在之前的SOTA模型QA-GNN下,随着训练推进,GNN 中节点和节点类型的 embedding 层的贡献越来越小,但边的表示一直保持着比较高的贡献率,对预测准确率有很大影响。
在第二张图中可以看出,QA-GNN的第二层 GNN 上,图注意力模块中的 key 和 query 几乎没有贡献,只有 value 比较有用。
在第三张图中,我们看到在三种有代表性的基于GNN的QA方法(QA-GNN, MHGRN, KagNet)中,不仅节点 embedding 层参数没用,节点的初始化也是可有可无的。
3 提出方法
综上我们发现,在用于QA的GNN中,很多模块对于推理都是可有可无的,因此我们尝试设计一个新的框架:
1)Node embeddings & relevance score. 实验中,初始节点(concept)的表示和相关性分数表示都是几乎没用的,因此删去;
2)Edge embeddings. 实验中边的表示看起来对于推理必不可少,保留;
3)Message passing layers. GNN内的线性层(query, key, value, etc)有比较低的sparse ratio,可能被过度参数化了,因此我们对于这些层使用了更少的参数。
4)Graph pooler. 最后,基于注意力的池化层得到优化后的节点表示,经过观察,我们发现key/value层可以被删去,graph pooler因此可以减少到一层线性变换。
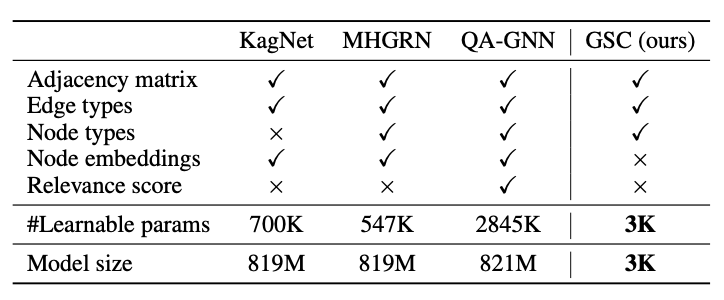
由此,我们进一步设计了一个简单有效的graph neural counter,实验表明,我们的方法在CommonsenseQAh和OpenBookQA两个数据集上取得了更好的效果。
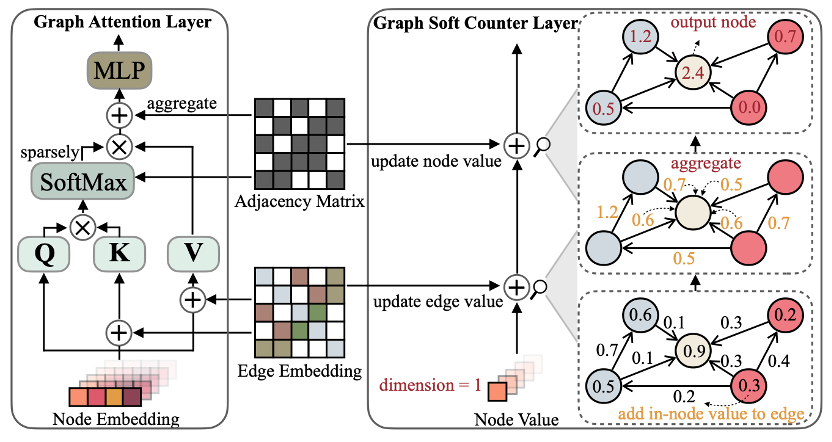
Graph Soft Counter 由两部分构成:
1)Edge encoder 是一个两层的MLP,输入边的 1-hot [u_s, e_{st}, u_t] 表示,最后输出一个 [0,1] 之间的浮点数,作为边的表示。其中 u_s, u_t 表示4种节点类型, e_{st} 表示 38 种边类型(这里的 38 种是 17 种边类型,加上问题/答案的边,以及所有类型的反向)。
2)Graph Soft Counter layer(GSC)是无参数的,只保留基本的图信息聚合与传播的操作。具体步骤如下图所示,一层 GSC 包含两步,即1)将节点的值加到边上;2)将边的值加到节点上。GSC的聚合操作就可以看做是对soft count的累加,可以把它看作现在主流GNN(比如GCN,GAT)一个有效的变体。
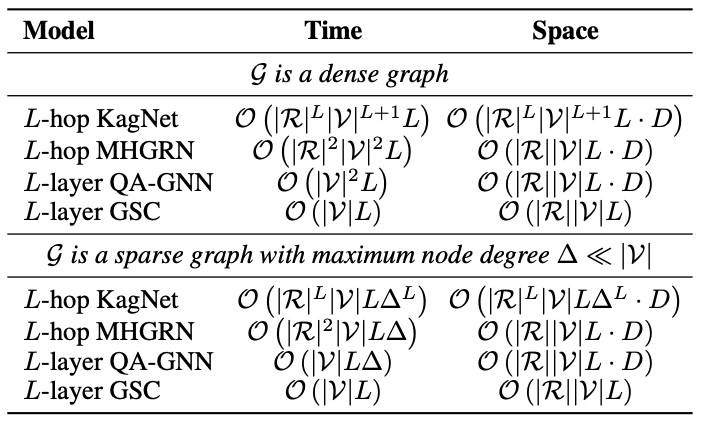
如表所示,GSC的计算复杂度比baseline减小不少。
4 实验
我们在 CommonsenseQA 和 OpenBookQA 两个数据集上进行了实验。
CommonsenseQA 是一个需要5项选择的QA任务,包含常识性的推理。而 OpenBookQA是一个4项选择的QA任务,蕴含一些需要用科学知识进行推理的题目。为了进行实验对比,我们基于同一个预训练模型RoBERTa-large,基于ConceptNet常识数据库,在两个数据集上进行了评测。
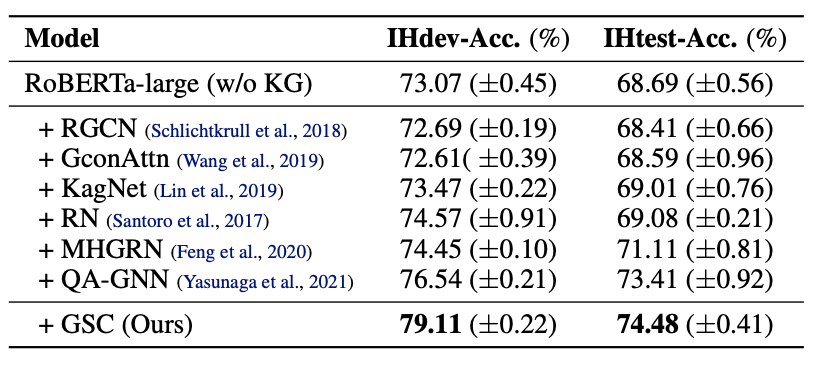
实验结果表明,在CommonsenseQA上,我们的方法GSC超越了所有基于GNN的方法,在dev上有平均2.57%的提升。

在CommonsenseQA的Leaderboard上,我们的方法也超过了所有基于GNN的QA方法,而目前SOTA的方法UnifiedQA采用了T5预训练模型,有11B参数,比GSC模型大30倍。
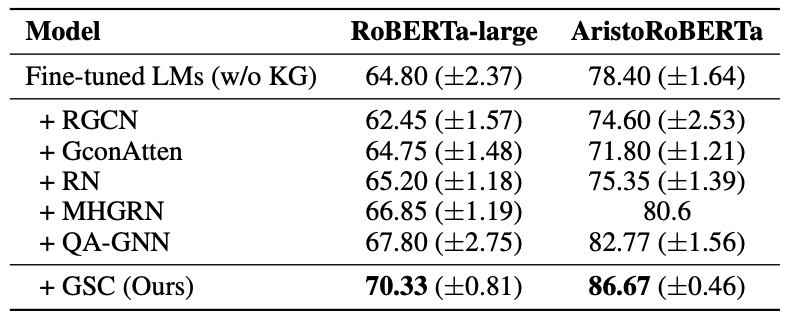
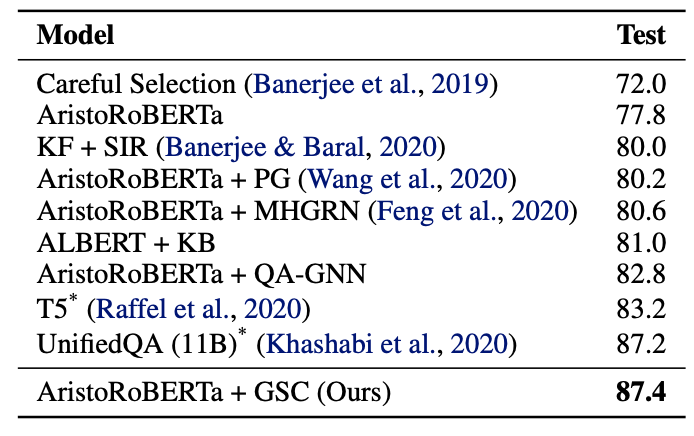
在OpenBookQA上,我们的表现甚至超过了UnifiedQA。
5 讨论
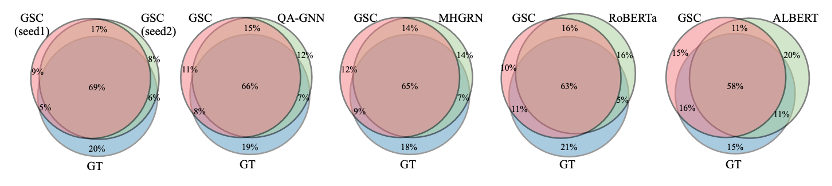
为了进一步证明GSC是否真的在进行推理,我们基于模型对ground truth的预测能力,将GSC和其他的基于GNN的QA方法进行了对比。
实验发现,两次GSC的预测结果的交集与ground truth的重合率有69%,而GSC与上面一些baseline的交集和ground truth也有60%左右的重合率,其中基于GNN 的模型重合率更大。这就证明了GSC拥有和GNN 差不多的推理能力。
另外,对于GSC预测结果的可解释性,我们通过打印每层输出的节点/边值,可以回溯模型对于答案的评分,如下图。
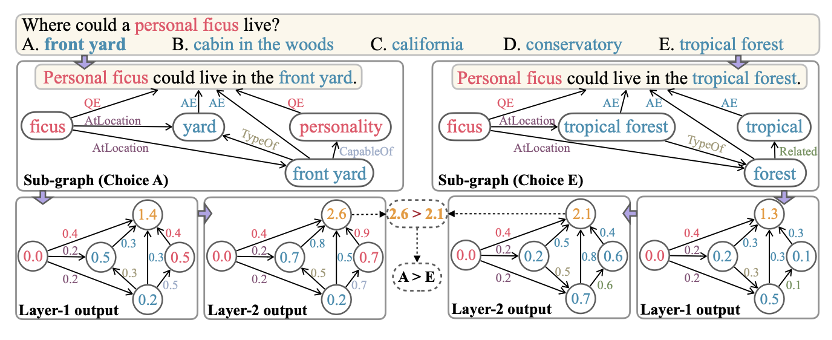
可以看到,对于每个答案选择过程,较高的soft count意味着这条边/这个节点更重要,可以对最终预测结果有更大贡献。此外,由于GSC只推理图上的边,不使用节点 embeddings,也使得模型能够更好地推广到有新实体的图。