![]()
![]()
![]() 哈喽大家好!
哈喽大家好!
本文将介绍SCR——一种简单且通用的图神经网络训练框架。具体地,我们提出了SCR和SCR-m两种利用一致性正则化(Consistency Regularization)训练图神经网络的策略。SCR利用未标记数据降低噪声对图神经网络的影响,来增强图神经网络的性能。在节点分类权威基准数据集OGB上,利用一致性正则化训练框架SCR,我们在ogbn-products, ogbn-mag, ogb-papers100M上都取得了排名第一的性能。相关代码已在github开源:GitHub - THUDM/SCR: This repository is an implementation of paper : SCR: Training Graph Neural Networks with Consistency Regularization 。
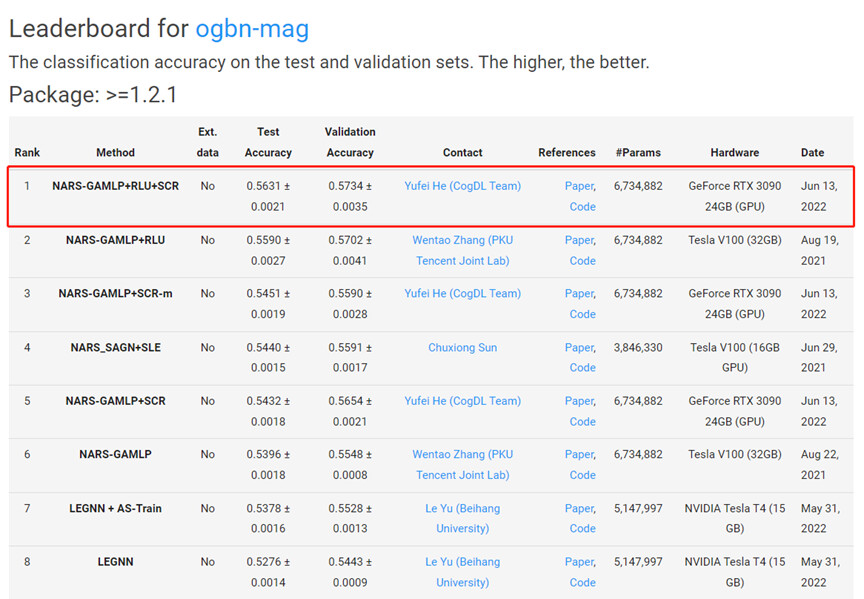
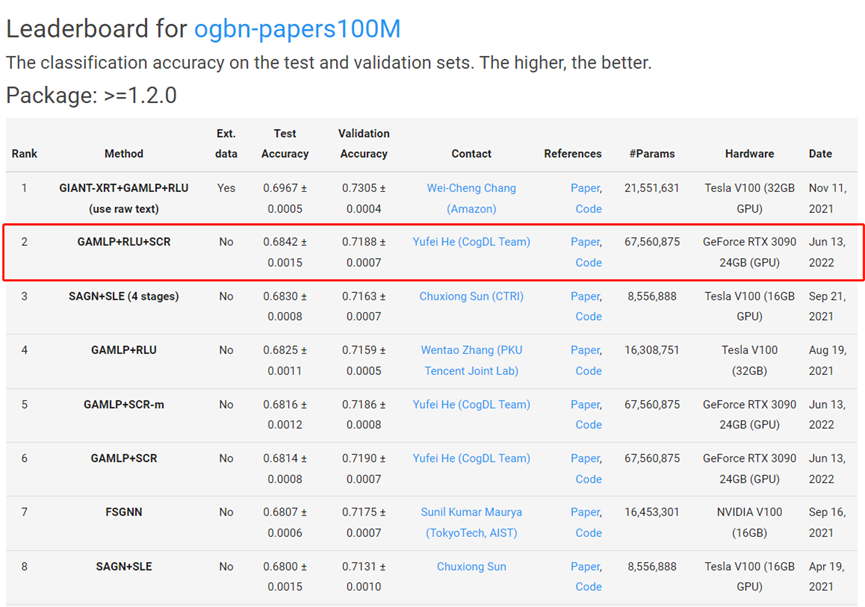
图基准数据集OGB
Open Graph Benchmark (OGB)作为目前图学习领域最常用的基准测试数据集,由斯坦福大学Jure Leskovec教授的研究团队建立。OGB提供了三类图学习任务的数据集和评测方式,分别关注节点属性、链接属性和图属性的预测问题。其中,节点分类任务是竞争最为激烈的一条赛道。ogbn-products是OGB中较为活跃的节点分类基准任务。该任务的数据集包含一个由亚马逊产品组成的联合购买网络:节点表示在Amazon中销售的产品,两个产品之间的边表示这些产品曾出现在同一笔订单中。ogbn-products数据集中仅有8%的节点被标记,如何利用未标记的节点是提升该任务效果的关键。 ogbn-papers100M数据集是一个由MAG索引的1.11亿篇论文的有向引文图。给定完整的ogbn-papers100M数据集,任务是预测在arXiv上发表的论文子集的主题领域。大多数节点(对应于非arXiv论文)都没有标签信息,只给出了它们的节点特征和参考信息。任务是利用整个引文网络来推断arXiv论文的标签。ogbn-mag数据集是一个由微软学术图谱(MAG)的一个子集组成的异质网络。它包含四种类型的实体–论文(736,389个节点)、作者(1,134,649个节点)、机构(8,740个节点)和研究领域(59,965个节点),以及连接两类实体的四种有向关系–作者 "附属于 "一个机构,作者 "撰写 "一篇论文,论文 "引用 "一篇论文,以及论文 “有一个研究领域的主题”。给定异质的ogbn-mag数据,任务是根据每篇论文的内容、参考文献、作者和作者单位,预测其发表地点(会议或期刊)。
图半监督学习背景
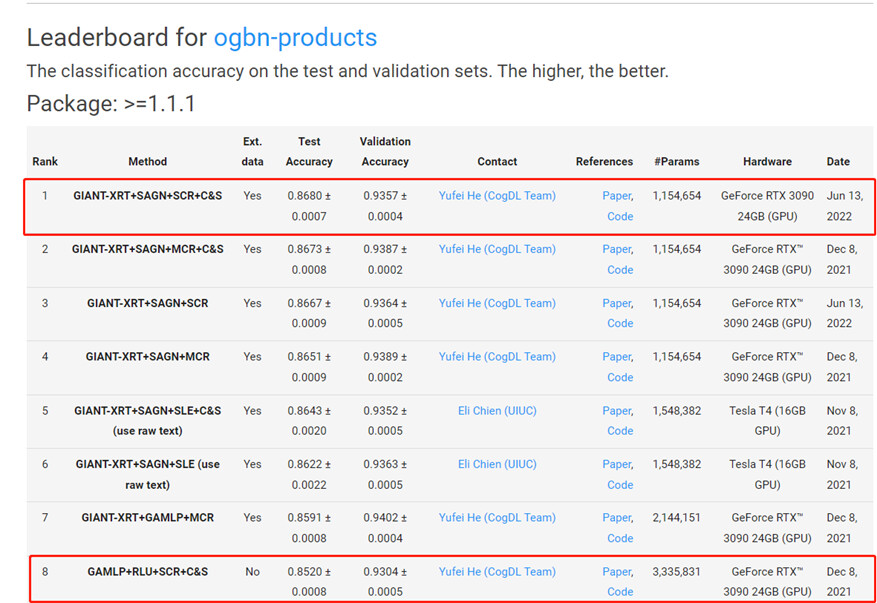
半监督学习一直是深度学习中的一个热点话题,其特点是标记数据和未标记数据同时参与模型的训练。在节点分类任务中,标记节点和未标记节点通过图结构相互关联。因此我们可以使用图神经网络将未标记节点上的信息融入标记节点中,使未标记节点间接地参与到模型训练中。尽管图神经网络提供了一种结合标记节点和未标记节点的方式,但由于图神经网络中的消息转播长度通常较短,只有标记节点附近的未标记节点能参与训练,网络中远离标记节点的部分很难对模型产生影响。为了更充分地利用网络中的未标记节点,我们尝试将图神经网络和其他半监督学习方法结合。在这个工作中,我们研究了一致性正则化(一种被广泛采用的半监督学习方法)如何帮助提高图神经网络的性能。我们探索了两种一致性正则化形式在图神经网络中的表现。一种是简单一致性正则化(SCR),另一种是Mean-teacher一致性正则化(SCR-m)。我们将一致性正则化方法应用到两种SOTA GNN模型上,并在三个OGB数据集上进行实验。实验结果表明,无论是否使用外部数据,两种图神经网络在加入一致性正则化后在节点分类任务上都获得了精度的提升。我们的方法目前在Open Graph Benchmark (OGB)的ogbn-products,ogbn-mag, ogbn-papers100M数据集上取得了Top 1的成绩。
一致性正则化方法SCR & SCR-m
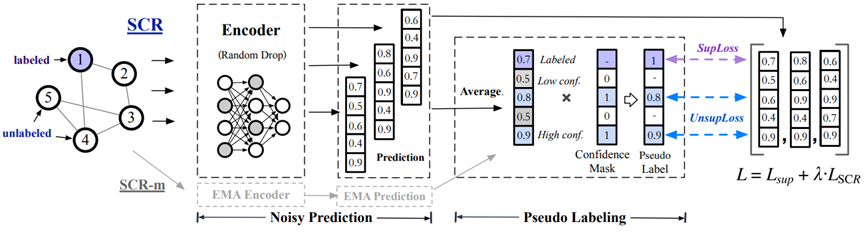
一致性正则化方法的假设是,对输入的微小扰动不应改变模型的输出。扰动可以通过操作输入(如数据增强)或向模型中注入噪声(如dropout)来获得。在这个工作中,我们利用两种方法对GNN进行一致性正则化。
一种方法被称为简单一致性正则化(SCR),其过程可以大致概括为:1. 通过模型得到同一个样本在受到不同扰动后的预测结果;2. 最小化这些预测之间的分歧。具体到节点分类场景,给定一个图 G ,我们通过一系列数据增强方法生成S个增强后的{(〖 G〗(s ) ) ̃ }(s=1)^S。我们将模型独立地应用于这些增广图上,得到每个节点 𝑖 的S个类分布。我们首先利用S个类分布构造一个“更合理”的预测目标𝑞𝑌|𝑖,然后最小化每个类分布与目标𝑞𝑌|𝑖的分歧。因此,无监督损失函数可以表示为:
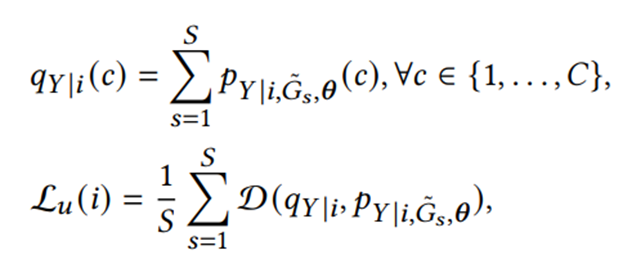
在这里,𝑞𝑌|𝑖是一个平滑后的预测,D是一个函数,衡量两个分布(如均方误差和交叉熵)之间的分歧。
另一种是利用基于Teacher-Student范式的Mean-teacher一致性正则化(SCR-m)。遵循Mean Teacher,我们通过计算student和teacher模型之间的一致性损失来指导模型的训练。Student模型的参数在训练中通过反向传播更新,而teacher模型的参数直接由student模型的指数移动平均(EMA)权值得出,不需要额外的反向传播。在这里采用的无监督损失函数:
![]()
实验结果
我们在3个OGB数据集上进行了一系列实验,展示了我们的性能,代码使用图深度学习框架CogDL(https://github.com/THUDM/cogdl)实现。
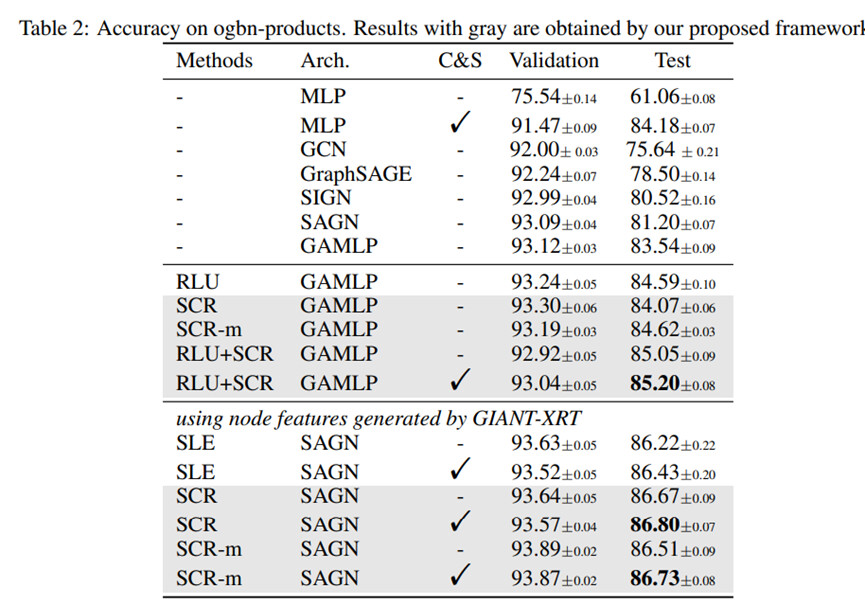
表2总结了我们的方法和基线方法在ogbn-products上的验证集和测试集的准确率。在GAMLP上使用SCR和SCR-m,测试集的预测精度分别提高了0.53%和1.08%。此外,SCR与RLU更加兼容。基于GAMLP(RLU),在应用SCR作为训练技术后,性能可以进一步提高0.46%,这是目前数据集上的最佳性能。在进一步应用C&S作为后处理步骤后,性能可以提高0.15%。通过使用GIANT-XRT提供的节点特征,我们的方法也可以带来性能的提升。将SCR和SCR-m应用于 SAGN模型,其性能超过了所有现有的基线。与SAGN(RLU)相比,测试精度提高了0.45%和0.29%。在加入C&S作为后处理后,测试精度提高了0.37%和0.30%。总的来说,我们提出的框架为ogbn-products带来了0.37%和0.46%的改进。在有GIANT-XRT特征和没有GIANT-XRT特征的ogbn-products上分别提高了0.37%和0.46%。
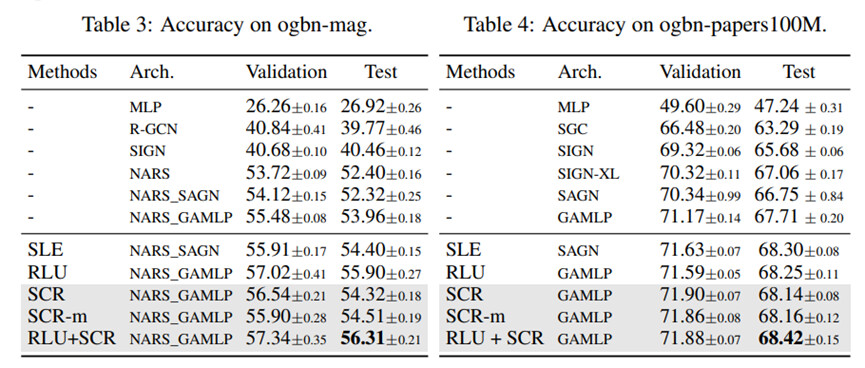
表3列出了我们的方法和基线方法在ogbn-mag数据集上的表现。我们使用 NARS_GAMLP作为基础模型,它显示出比NARS_SAGN更好的性能。与NARS_GAMLP相比 与NARS_GAMLP相比,应用SCR时,测试准确率可提高0.36%和0.55%。和SCR-m。同时,当在NARS_GAMLP(RLU)中加入SCR时,其性能仍可提高0.41%。
表4显示了所有方法在ogbn-papers100M数据集上的表现。通过在GAMLP上使用SCR和SCR-m,测试精度可以提高0.43%和0.45%。此外,通过将SCR应用于GAMLP(RLU),其最终性能超过了所有比较的基线。
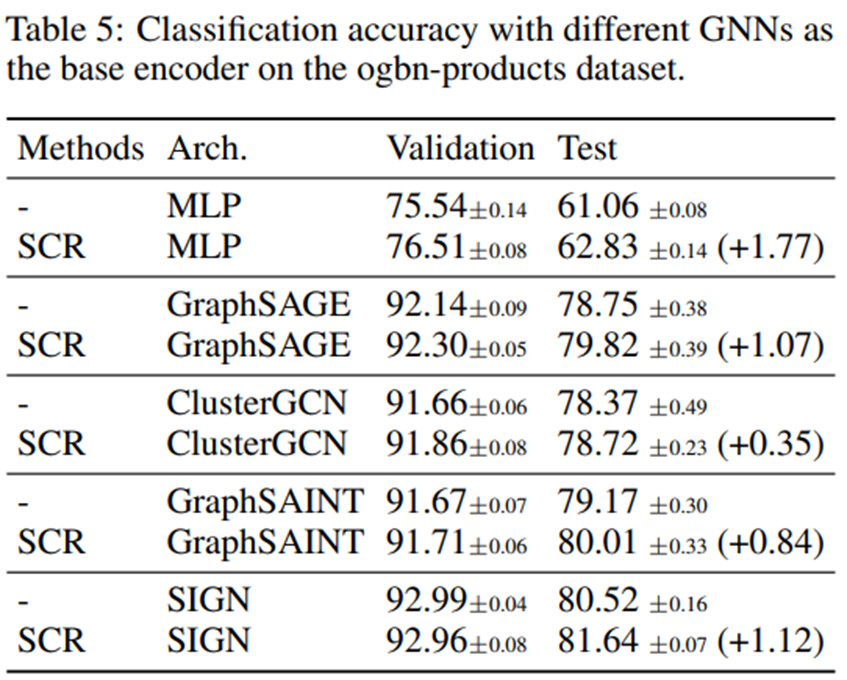
根据设计,SCR框架是一个通用的一致性正则化框架,目标是改善基础图模型。如上所示,它可以帮助GAMLP和SAGN–之前在三个OGB排行榜上的SOTA模型–提高它们的性能。在此,我们将研究SCR是否能够广泛地帮助其他图编码器。具体来说,我们考虑将以下五个架构,即MLP、GraphSAGE、ClusterGCN、GraphSAINT和SIGN,作为SCR的基础图编码器。表5报告了原始模型和SCR在ogbn-products上的结果。我们观察到SCR框架为所有五个编码器带来了一致的性能提升,进一步证明了SCR是一种通用的一致性正则化技术,可以使GNN的性能得到提升。