论文链接:https://ogb.stanford.edu/paper/kddcup2021/mag240m_BD-PGL.pdf
代码仓库:PGL/examples/kddcup2021/MAG240M/r_unimp at main · PaddlePaddle/PGL · GitHub
Background
KDD Cup 2021 的 OGB-LSC竞赛分为三个不同的赛道,涵盖了节点级别,边级别以及图级别的预测任务。其中,节点级别的赛道是在MAG240M‑LSC ,一个大规模引文网络上进行节点级预测。 MAG240M‑LSC 是从 Microsoft Academic Graph (MAG) 中提取的异构学术图,具有论文、作者和机构之间的多重关系。参与者需要预测与出版物相对应的主题。
Dataset Introduction
MAG240M‑LSC 中的节点代表论文、作者和机构。共有三种类型的边缘:论文‑引用‑论文、作者‑写‑论文、作者‑附属机构。在 121M 的论文节点中,大约有 140 万个节点来自 ARXIV,标注了 153 个 ARXIV 主题领域。节点的特征由强大的预训练语言模型 RoBERTA 提取。任务是将给定 ARXIV 论文的主要学科领域预测为普通的多类分类问题。指标是分类准确度。
Methods
在这个比赛中,作者团队选择R-GAT模型作为基线模型,并在此基础上做了一些修改以进一步改进模型性能
Relation-wise Neighborhood Sampling
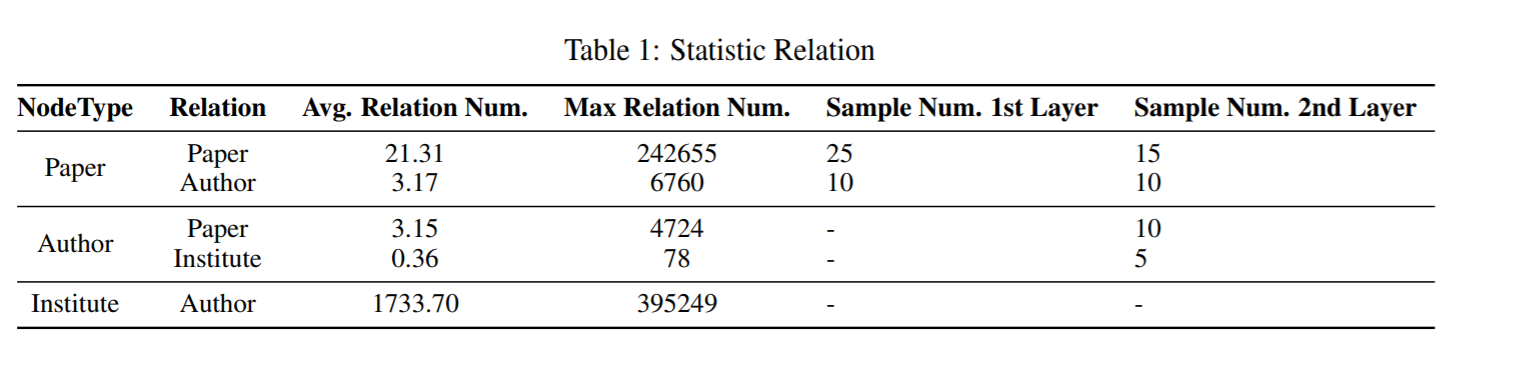
R-GAT的原始实现在邻域采样期间将所有邻域视为齐次图。然而,它们忽略采样偏差执行关系型GAT聚合。在充分研究了邻域分布之后,作者发现齐次抽样方法不能保证每个关系至少有一个邻域。因为它递归地对第一层中的25个邻居和第二层中的15个邻居进行采样,但引用论文关系的论文比作者撰写论文的论文更多,因此,对于每个层对应的每个关系,作者团队使用不同数量的采样邻居执行关系式采样
Relation-wise BatchNorm
此外,归一化已被证明是深度残差图神经网络的一种有效技术。R-GAT的原始实现只是在不同关系之间进行特征聚合后插入BatchNorm模块。并且所有节点共享相同的运行均值和偏差统计。然而,论文节点在每个训练批次中占多数,导致作者和研究所节点的统计数据不准确。为了解决这个问题,作者将BatchNorm放在邻域聚合之后的层上。并且防止节点和边类型之间的参数和统计信息共享。
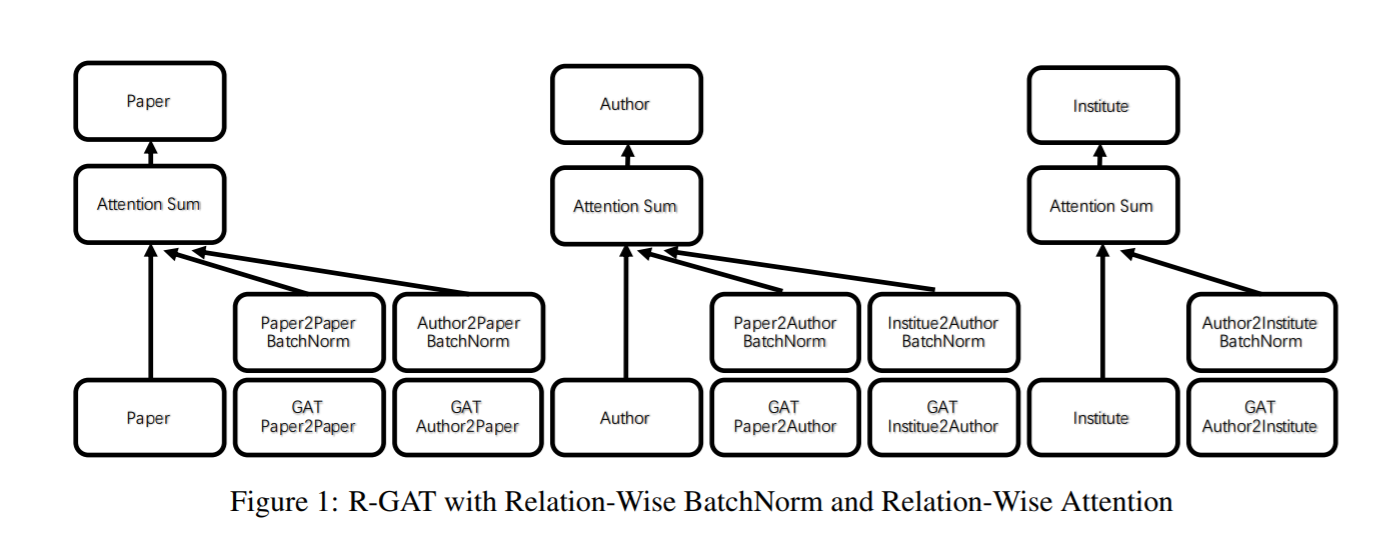
Relation-wise Attention
此外,边缘关系在不同节点上可能有不同的贡献。因此,为了取代关系之间的特征求和,我们设计了一个加权注意求和层,用于按关系进行特征聚合,如图所示
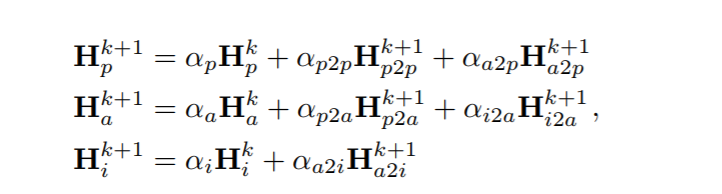
其中Hp、Ha、Hi表示论文、作者和研究所节点的特征。而Hp2p、Ha2p、Hp2a、Ha2i、Hi2a是来自不同关系的聚合表示。利用剩余连接和邻居之间的注意力加权和计算每个隐藏节点。注意力权重的计算如下:
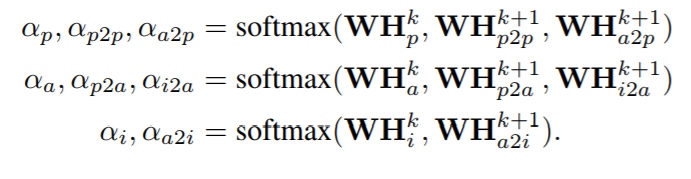
Masked Label Prediction
百度提出了一种在训练和推理阶段结合标签传播和特征传播的模型UNiMP。它还指出,在训练集中利用观察到的标签可以极大地改进预测。因为标签在节点分类中可能是不明确的。例如,一篇论文可以包含几个不同的主题,这可能会让GNN模型感到困惑。最直接的证据是,训练集的精度很难达到高精度。因此,作者采用了UNiMP中的思想,并按照论文中所述执行掩蔽标签预测。
在训练时,作者将标签嵌入到除目标标签外所有观察到标签的论文节点上。此外,作者发现在训练期间在所有论文节点上添加随机标签可以使模型在预测方面更具鲁棒性。因此猜测,随机标签噪声迫使模型更多地依赖于节点特征而不是标签进行预测,因为验证中未标记的节点连接到的标记节点少于训练集中的节点。
Post-Smoothing
在训练模型并进行预测之后,仍有一些技巧需要进一步改进。作者发现通过修改标准标签传播技术的简单后处理步骤可以提高性能。作者发现在使用UNiMP技术使用标签信息进行训练后。简单的C&S后处理步骤对预测的影响很小。然而,如果对具有更高同态比率的构造论文-论文图执行平滑,可以实现0.05%-0.1%的改进。因此,作者在不同的纸图上通过简单投票策略研究验证准确性,如下所示:

作者发现,对合著者图的简单投票可以实现更高的预测精度,因此平滑策略可以制定如下:

其中α控制自身和邻居预测之间的重要性,k表示迭代次数。与C&S实现不同,作者在每次迭代后评估验证精度,并对k和α执行早期停止。在α=0.8的几步(3或4)后平滑后,预测可以达到收敛。
Network Embeddings
训练深度图神经网络存在困难,例如执行时间和记忆的指数增长。因此,为了利用节点之间的结构信息,作者在这些异构网络上训练网络嵌入。 Metapath2Vec是异构网络上的经典表示学习算法之一。metapath2vec模型将基于元路径的随机游动形式化,以构建节点的异构邻域,然后训练异构跳过图模型以执行节点嵌入。作者训练得到网络嵌入,然后除了所提供的768维语义特征之外将其拼接。
Experiments
Best Single Model
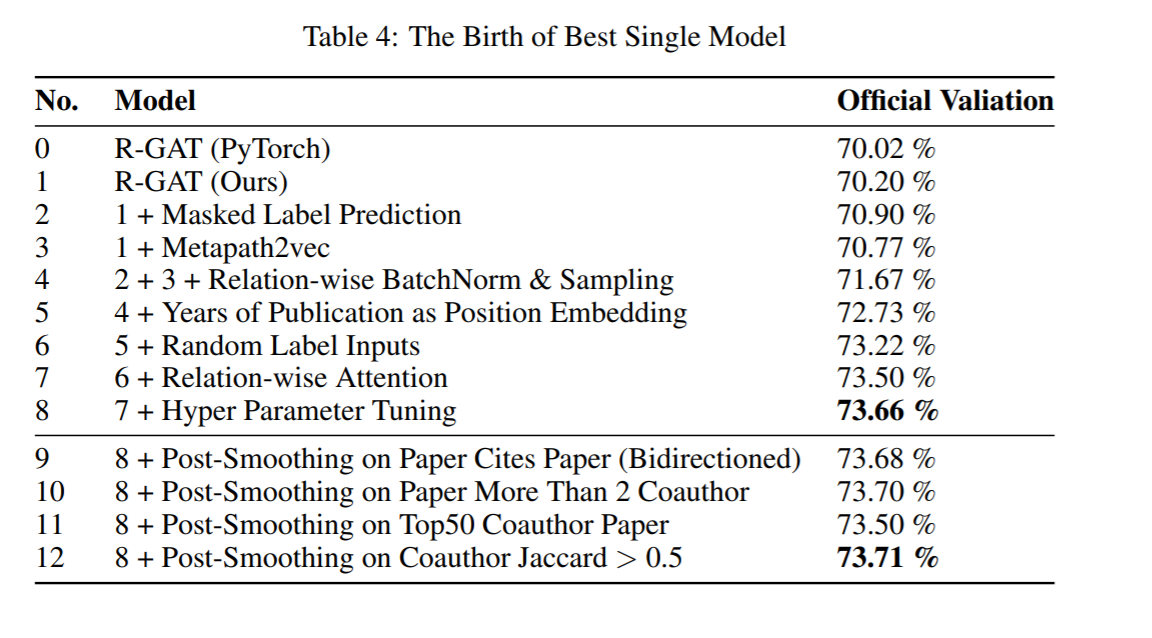
图中显示了模型的整个优化过程。在探索模型架构的过程中,作者为每个架构升级保留了几乎相似的超参数设置。升级后的模型从70.20%提升到73.66%。
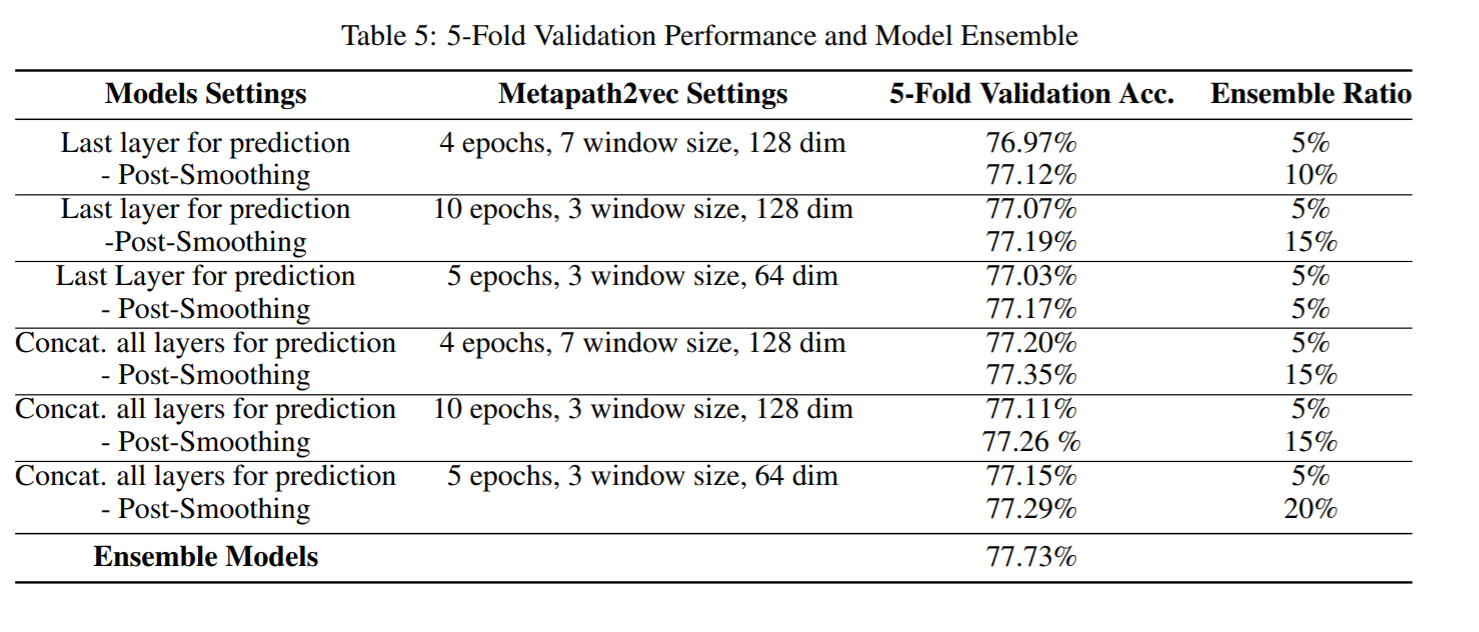
Ensemble Models
最后,作者用6个不同的超参数训练模型。此外,作者发现将所有层的节点表示串联起来进行最终预测可以实现进一步的改进。然而,作者没有足够的时间进行官方验证分割。最终集合预测由30个模型获得,验证精度为77.73%。